Welcome to the Nanopore Community
Order MinION devices and consumables
Visit vwr.comLigation sequencing gDNA - PCR barcoding (SQK-LSK109 with EXP-PBC001)
Version for device: MinION
Introduction to the protocol
Overview of the protocol
-
PCR Barcoding Expansion 1-12 features
This kit is recommended for users who:
- want to optimise their sequencing experiment for throughput
- require control over read length
- would like to utilise upstream processes such as size selection or whole genome amplification
- want to multiplex up to 12 different samples
-
Introduction to the PCR barcoding protocol
This protocol describes how to carry out PCR barcoding of DNA using the Ligation Sequencing Kit 1D (SQK-LSK109) and the PCR Barcoding Expansion 1-12 (EXP-PBC001). It is highly recommended that a Lambda control experiment is completed first to become familiar with the technology.
Steps in the sequencing workflow:
Prepare for your experiment
You will need to:
- Extract your DNA, and check its length, quantity and purity.
The quality checks performed during the protocol are essential in ensuring experimental success.
- Ensure you have your sequencing kit, the correct equipment and third-party reagents
- Download the software for acquiring and analysing your data
- Check your flow cell to ensure it has enough pores for a good sequencing runLibrary preparation
You will need to:
- Prepare the DNA ends for adapter attachment
- Attach barcoding adapters supplied in the kit to the DNA ends
- Amplify each barcoded sample by PCR, then pool the samples together
- Repair the DNA, and prepare the DNA ends for adapter attachment
- Attach sequencing adapters supplied in the kit to the DNA ends
- Prime the flow cell, and load your DNA library into the flow cell
Sequencing and analysis
You will need to:
- Start a sequencing run using the MinKNOW software, which will collect raw data from the device and convert it into basecalled reads
- Start the EPI2ME software and select the barcoding workflow

Equipment and consumables
- Materials
-
- <1 µg of each DNA sample to be barcoded in 45 µl
- PCR Barcoding Expansion 1-12 (EXP-PBC001)
- Ligation Sequencing Kit (SQK-LSK109)
- Flow Cell Priming Kit (EXP-FLP002)
- Consumables
-
- NEB Blunt/TA Ligase Master Mix (NEB, M0367)
- Agencourt AMPure XP beads (Beckman Coulter, A63881)
- NEBNext® Companion Module for Oxford Nanopore Technologies® Ligation Sequencing (NEB, E7180S or E7180L). Alternatively, you can use the NEBNext® products below:
- NEBNext FFPE Repair Mix (NEB, M6630)
- NEBNext Ultra II End repair/dA-tailing Module (NEB, E7546)
- NEBNext Quick Ligation Module (NEB, E6056)
- 1.5 ml Eppendorf DNA LoBind tubes
- 0.2 ml thin-walled PCR tubes
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Freshly prepared 70% ethanol in nuclease-free water
- LongAmp Taq 2X Master Mix (e.g. NEB, cat # M0287)
- Equipment
-
- Hula mixer (gentle rotator mixer)
- Magnetic rack, suitable for 1.5 ml Eppendorf tubes
- Microfuge
- Vortex mixer
- Thermal cycler
- P1000 pipette and tips
- P200 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
- P2 pipette and tips
- Ice bucket with ice
- Timer
- Optional Equipment
-
- Agilent Bioanalyzer (or equivalent)
- Qubit fluorometer (or equivalent for QC check)
- Eppendorf 5424 centrifuge (or equivalent)
-
For this protocol, you will need <1 µg of each DNA sample to be barcoded in 45 µl.
-
Input DNA
How to QC your input DNA
It is important that the input DNA meets the quantity and quality requirements. Using too little or too much DNA, or DNA of poor quality (e.g. highly fragmented or containing RNA or chemical contaminants) can affect your library preparation.
For instructions on how to perform quality control of your DNA sample, please read the Input DNA/RNA QC protocol.
Chemical contaminants
Depending on how the DNA is extracted from the raw sample, certain chemical contaminants may remain in the purified DNA, which can affect library preparation efficiency and sequencing quality. Read more about contaminants on the Contaminants page of the Community.
-
NEBNext® Companion Module for Oxford Nanopore Technologies® Ligation Sequencing
For customers new to nanopore sequencing, we recommend buying the NEBNext® Companion Module for Oxford Nanopore Technologies® Ligation Sequencing (catalogue number E7180S or E7180L), which contains all the NEB reagents needed for use with the Ligation Sequencing Kit.
Please note, for our amplicon protocols, NEBNext FFPE DNA Repair Mix and NEBNext FFPE DNA Repair Buffer are not required.
-
PCR Barcoding Expansion 1-12 (EXP-PBC001) contents

Name Acronym Cap colour No. of vials Fill volume per vial (μl) PCR Barcode 1-12 BC1-12 Clear 12 20 Barcode Adapter BCA Blue stripe 1 260 -
Ligation Sequencing Kit contents (SQK-LSK109)

Name Acronym Cap colour No. of vials Fill volume per vial (µl) DNA CS DCS Yellow 1 50 Adapter Mix AMX Green 1 40 Ligation Buffer LNB Clear 1 200 L Fragment Buffer LFB White cap, orange stripe on label 2 1,800 S Fragment Buffer SFB Grey 2 1,800 Sequencing Buffer SQB Red 2 300 Elution Buffer EB Black 1 200 Loading Beads LB Pink 1 360 -
Flow Cell Priming Kit contents (EXP-FLP002)
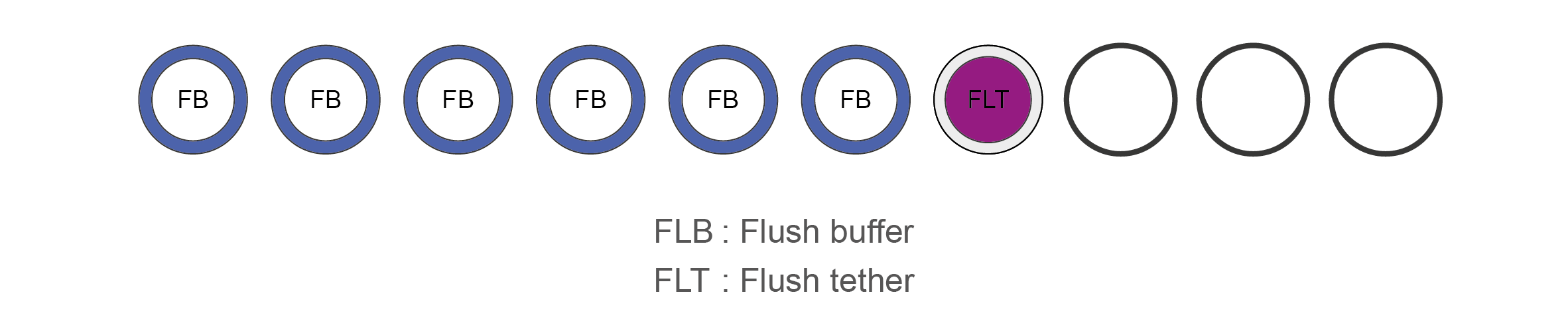
Name Acronym Cap colour No. of vials Fill volume per vial (μl) Flush Buffer FB Blue 6 1,170 Flush Tether FLT Purple 1 200



Computer requirements and software
Computer requirements and software
-
MinION Mk1B IT requirements
Sequencing on a MinION Mk1B requires a high-spec computer or laptop to keep up with the rate of data acquisition. For more information, refer to the MinION Mk1B IT requirements document.
-
MinION Mk1C IT requirements
The MinION Mk1C contains fully-integrated compute and screen, removing the need for any accessories to generate and analyse nanopore data. For more information refer to the MinION Mk1C IT requirements document.
-
MinION Mk1D IT requirements
Sequencing on a MinION Mk1D requires a high-spec computer or laptop to keep up with the rate of data acquisition. For more information, refer to the MinION Mk1D IT requirements document.
-
Software for nanopore sequencing
MinKNOW
The MinKNOW software controls the nanopore sequencing device, collects sequencing data and basecalls in real time. You will be using MinKNOW for every sequencing experiment to sequence, basecall and demultiplex if your samples were barcoded.
For instructions on how to run the MinKNOW software, please refer to the MinKNOW protocol.
EPI2ME (optional)
The EPI2ME cloud-based platform performs further analysis of basecalled data, for example alignment to the Lambda genome, barcoding, or taxonomic classification. You will use the EPI2ME platform only if you would like further analysis of your data post-basecalling.
For instructions on how to create an EPI2ME account and install the EPI2ME Desktop Agent, please refer to this link.
-
Check your flow cell
We highly recommend that you check the number of pores in your flow cell prior to starting a sequencing experiment. This should be done within 12 weeks of purchasing for MinION/GridION/PromethION or within four weeks of purchasing Flongle Flow Cells. Oxford Nanopore Technologies will replace any flow cell with fewer than the number of pores in the table below, when the result is reported within two days of performing the flow cell check, and when the storage recommendations have been followed. To do the flow cell check, please follow the instructions in the Flow Cell Check document.
Flow cell Minimum number of active pores covered by warranty Flongle Flow Cell 50 MinION/GridION Flow Cell 800 PromethION Flow Cell 5000
Library preparation
End-prep
End-prep
- Materials
-
- <1 µg of each DNA sample to be barcoded in 45 µl
- Consumables
-
- NEBNext Ultra II End repair/dA-tailing Module (NEB, E7546)
- Freshly prepared 70% ethanol in nuclease-free water
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Agencourt AMPure XP beads (Beckman Coulter, A63881)
- 0.2 ml thin-walled PCR tubes
- Equipment
-
- Thermal cycler
- Ice bucket with ice
- Microfuge
- Magnetic rack, suitable for 1.5 ml Eppendorf tubes
- Optional Equipment
-
- Qubit fluorometer (or equivalent for QC check)
-
Prepare the DNA in nuclease-free water.
- Transfer <1 μg DNA of each sample into a fresh 0.2 ml PCR tube or plate
- Adjust the volume to 45 μl with nuclease-free water
- Mix thoroughly by flicking the tube to avoid unwanted shearing
- Spin down briefly in a microfuge
-
Using a separate 0.2 ml thin-walled PCR tube for each DNA sample to be barcoded, set up the end-repair / dA-tailing reactions as follows:
Between each addition, pipette mix 10-20 times.
Reagent Volume <1 µg DNA 45 µl Ultra II End-prep reaction buffer 7 µl Ultra II End-prep enzyme mix 3 µl Nuclease-free water 5 µl Total 60 µl -
Mix by pipetting.
-
Using a thermal cycler, incubate at 20°C for 5 minutes and 65°C for 5 minutes.
-
Transfer each sample to a separate 1.5 ml Eppendorf DNA LoBind tube.
-
Resuspend the AMPure XP beads by vortexing.
-
Add 60 µl of resuspended AMPure XP beads to the end-prep reaction and mix by pipetting.
-
Incubate on a Hula mixer (rotator mixer) for 5 minutes at room temperature.
-
Prepare sufficient fresh 70% ethanol in nuclease-free water.
-
Place on a magnetic rack, allow beads to pellet and pipette off supernatant.
-
Keep the tube on the magnet and wash the beads with 180 µl of freshly-prepared 70% ethanol without disturbing the pellet. Remove the ethanol using a pipette and discard.
-
Repeat the previous step.
-
Spin down and place the tubes back on the magnet. Pipette off any residual ethanol. Allow to dry for ~30 seconds, but do not dry the pellet to the point of cracking.
-
Remove the tubes from the magnetic rack and resuspend the pellet in 31 µl nuclease-free water. Incubate for 2 minutes at room temperature.
-
Pellet the beads on a magnet until the eluate is clear and colourless.
-
Remove eluate once it is clear and colourless. Transfer each eluted sample to a new 0.2 ml thin-walled PCR tube.
-
Quantify 1 µl of end-prepped DNA using a Qubit fluorometer - recovery aim >700 ng.
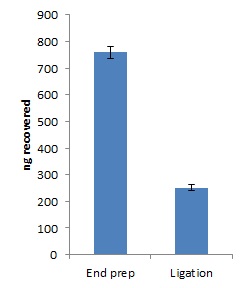
Ligation of Barcode Adapter
- Materials
-
- Barcode Adapter (BCA)
- Consumables
-
- 1.5 ml Eppendorf DNA LoBind tubes
- NEB Blunt/TA Ligase Master Mix (NEB, cat # M0367)
- Agencourt AMPure XP beads (Beckman Coulter, A63881)
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Freshly prepared 70% ethanol in nuclease-free water
- 10 mM Tris-HCl pH 8.5
- Equipment
-
- Microfuge
- Hula mixer (gentle rotator mixer)
- Vortex mixer
- Magnetic rack, suitable for 1.5 ml Eppendorf tubes
- Ice bucket with ice
- Optional Equipment
-
- Agilent Bioanalyzer (or equivalent)
-
Add the reagents in the order given below, mixing by pipetting between each sequential addition:
Between each addition, pipette mix 10-20 times.
Reagent Volume End prep DNA 30 µl Barcode Adapter 20 µl Blunt/TA Ligase Master Mix 50 µl Total 100 µl -
Mix gently by flicking the tube, and spin down.
-
Incubate the reaction for 10 minutes at room temperature.
-
Resuspend the AMPure XP beads by vortexing.
-
Add 40 µl of resuspended AMPure XP beads to the reaction and mix by flicking the tube.
-
Incubate on a Hula mixer (rotator mixer) for 5 minutes at room temperature.
-
Prepare 500 μl of fresh 70% ethanol in nuclease-free water.
-
Spin down the sample and pellet on a magnet. Keep the tube on the magnet, and pipette off the supernatant.
-
Keep the tube on the magnet and wash the beads with 200 µl of freshly prepared 70% ethanol without disturbing the pellet. Remove the ethanol using a pipette and discard.
-
Repeat the previous step.
-
Spin down and place the tube back on the magnet. Pipette off any residual 70% ethanol. Briefly allow to dry.
-
Remove the tube from the magnetic rack and resuspend pellet in 25 µl nuclease-free water. Incubate for 2 minutes at room temperature.
-
Pellet the beads on a magnet until the eluate is clear and colourless.
-
Remove and retain 15 µl of eluate into a clean 1.5 ml Eppendorf DNA LoBind tube.
- Remove and retain the eluate which contains the DNA library in a clean 1.5 ml Eppendorf DNA LoBind tube
- Dispose of the pelleted beads
-
Quantify 1 µl of end-prepped DNA using a Qubit fluorometer.
-
Dilute the library to a concentration of 10 ng/µl with nuclease-free water or 10 mM Tris-HCl pH 8.5.
Barcoding PCR
Barcoding PCR
- Materials
-
- PCR Barcode Primers (BC01-12, at 10 µM)
- Consumables
-
- LongAmp Taq 2X Master Mix (e.g. NEB, cat # M0287)
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- 1.5 ml Eppendorf DNA LoBind tubes
- Agencourt AMPure XP beads (Beckman Coulter™, A63881)
- Freshly prepared 70% ethanol in nuclease-free water
- Equipment
-
- Thermal cycler
- Magnetic rack
- Hula mixer (gentle rotator mixer)
-
Set up a barcoding PCR reaction as follows for each library:
The following is written for LongAmp Taq, but can be adapted for use with other polymerases.
Between each addition, pipette mix 10-20 times.
Reagent Volume PCR Barcode (one of BC01-BC12, at 10 µM) 2 µl 10 ng/µl adapter ligated template 2 µl LongAmp Taq 2x master mix 50 µl Nuclease-free water 46 µl Total volume 100 µl -
If the amount of input material is altered, the number of PCR cycles may need to be adjusted to produce the same yield.
-
Mix gently by flicking the tube, and spin down.
-
Amplify using the following cycling conditions:
Cycle step Temperature Time No. of cycles Initial denaturation 95 °C 3 mins 1 Denaturation 95 °C 15 secs 12-15 (b) Annealing 62 °C (a) 15 secs (a) 12-15 (b) Extension 65 °C (c) dependent on length of target fragment (d) 12-15 (b) Final extension 65 °C dependent on length of target fragment (d) 1 Hold 4 °C ∞ a. This is specific to the Oxford Nanopore primer and should be maintained
b. Adjust accordingly if input quantities are altered
c. This temperature is determined by the type of polymerase that is being used (given here for LongAmp Taq polymerase)
d. Adjust accordingly for different lengths of amplicons and the type of polymerase that is being used. Oxford Nanopore R&D teams standardly use 8 min for DNA fragmented to 8 kb.
-
Transfer each sample to a separate 1.5 ml Eppendorf DNA LoBind tube.
-
Resuspend the AMPure XP beads by vortexing.
-
Add 60 µl of resuspended AMPure XP beads to each reaction and mix by flicking the tube.
-
Incubate on a Hula mixer (rotator mixer) for 5 minutes at room temperature.
-
Prepare sufficient fresh 70% ethanol in nuclease-free water.
-
Spin down the samples and pellet the beads on a magnet until the eluate is clear and colourless. Keep the tubes on the magnet and pipette off the supernatant.
-
Keep the tube on the magnet and wash the beads with 200 µl of freshly prepared 70% ethanol without disturbing the pellet. Remove the ethanol using a pipette and discard.
-
Repeat the previous step.
-
Spin down and place the tubes back on the magnet. Pipette off any residual ethanol. Allow to dry for ~30 seconds, but do not dry the pellet to the point of cracking.
-
Remove the tubes from the magnetic rack and resuspend each pellet in 10 µl nuclease-free water. Incubate for 2 minutes at room temperature.
-
Pellet the beads on a magnet until the eluate is clear and colourless.
-
Remove and retain 10 µl of eluate into a clean 1.5 ml Eppendorf DNA LoBind tube.
- Dispose of the pelleted beads
-
Quantify the barcoded library using standard techniques, and pool all barcoded libraries in the desired ratios in a 1.5 ml DNA LoBind Eppendorf tube.
-
Prepare 1 µg of pooled barcoded libraries in 47 µl nuclease-free water.
End-prep
End-prep
- Materials
-
- Pooled barcoded DNA
- DNA Control Sample (DCS)
- AMPure XP Beads (AXP)
- Consumables
-
- 1.5 ml Eppendorf DNA LoBind tubes
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- NEBNext® Ultra II End Repair / dA-tailing Module (NEB, E7546)
- Freshly prepared 80% ethanol in nuclease-free water
- Qubit™ Assay Tubes (Invitrogen, Q32856)
- Qubit dsDNA HS Assay Kit (Invitrogen, Q32851)
- Equipment
-
- P1000 pipette and tips
- P100 pipette and tips
- P10 pipette and tips
- Thermal cycler
- Microfuge
- Hula mixer (gentle rotator mixer)
- Magnetic rack
- Ice bucket with ice
- Optional Equipment
-
- Qubit fluorometer (or equivalent for QC check)
-
Thaw DNA Control Sample (DCS) at room temperature, spin down, mix by pipetting, and place on ice.
-
Prepare the NEBNext Ultra II End Repair / dA-tailing Module reagents in accordance with manufacturer's instructions, and place on ice:
For optimal performance, NEB recommend the following:
Thaw all reagents on ice.
Ensure the reagents are well mixed.
Note: Do not vortex the Ultra II End Prep Enzyme Mix.Always spin down tubes before opening for the first time each day.
The NEBNext Ultra II End Prep Reaction Buffer may contain a white precipitate. If this occurs, allow the mixture(s) to come to room temperature and pipette the buffer several times to break up the precipitate, followed by a quick vortex to mix.
-
In a 0.2 ml thin-walled PCR tube, mix the following:
Reagent Volume DNA Control Sample (DCS) 1 µl DNA 49 µl Ultra II End-prep Reaction Buffer 7 µl Ultra II End-prep Enzyme Mix 3 µl Total 60 µl -
Ensure the components are thoroughly mixed by pipetting.
-
Using a thermal cycler, incubate at 20°C for 5 minutes and 65°C for 5 minutes.
-
Resuspend the AMPure XP Beads (AXP) by vortexing.
-
Transfer the DNA sample to a clean 1.5 ml Eppendorf DNA LoBind tube.
-
Add 60 µl of resuspended the AMPure XP Beads (AXP) to the end-prep reaction and mix by flicking the tube.
-
Incubate on a Hula mixer (rotator mixer) for 5 minutes at room temperature.
-
Prepare 500 μl of fresh 80% ethanol in nuclease-free water.
-
Spin down the sample and pellet on a magnet until supernatant is clear and colourless. Keep the tube on the magnet, and pipette off the supernatant.
-
Keep the tube on the magnet and wash the beads with 200 µl of freshly prepared 80% ethanol without disturbing the pellet. Remove the ethanol using a pipette and discard.
-
Repeat the previous step.
-
Spin down and place the tube back on the magnet. Pipette off any residual ethanol. Allow to dry for ~30 seconds, but do not dry the pellet to the point of cracking.
-
Remove the tube from the magnetic rack and resuspend the pellet in 61 µl nuclease-free water. Incubate for 2 minutes at room temperature.
-
Pellet the beads on a magnet until the eluate is clear and colourless, for at least 1 minute.
-
Remove and retain 61 µl of eluate into a clean 1.5 ml Eppendorf DNA LoBind tube.
-
Optional ActionQuantify 1 µl of eluted sample using a Qubit fluorometer.
Adapter ligation and clean-up
Adapter ligation and clean-up
- Materials
-
- Adapter Mix (AMX)
- Ligation Buffer (LNB)
- Long Fragment Buffer (LFB)
- Short Fragment Buffer (SFB)
- Elution Buffer (EB)
- Consumables
-
- NEBNext Quick Ligation Module (NEB, E6056)
- 1.5 ml Eppendorf DNA LoBind tubes
- Agencourt AMPure XP beads (Beckman Coulter™, A63881)
- Equipment
-
- Magnetic rack
- Microfuge
- Vortex mixer
- P1000 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
-
Spin down the Adapter Mix (AMX) and Quick T4 Ligase, and place on ice.
-
Thaw Ligation Buffer (LNB) at room temperature, spin down and mix by pipetting. Due to viscosity, vortexing this buffer is ineffective. Place on ice immediately after thawing and mixing.
-
Thaw the Elution Buffer (EB) at room temperature and mix by vortexing. Then spin down and place on ice.
-
To enrich for DNA fragments of 3 kb or longer, thaw one tube of Long Fragment Buffer (LFB) at room temperature, mix by vortexing, spin down and place on ice.
-
To retain DNA fragments of all sizes, thaw one tube of Short Fragment Buffer (SFB) at room temperature, mix by vortexing, spin down and place on ice.
-
In a 1.5 ml Eppendorf DNA LoBind tube, mix in the following order:
Between each addition, pipette mix 10 - 20 times.
Reagent Volume DNA sample from the previous step 60 µl Ligation Buffer (LNB) 25 µl NEBNext Quick T4 DNA Ligase 10 µl Adapter Mix (AMX) 5 µl Total 100 µl -
Ensure the components are thoroughly mixed by pipetting, and spin down.
-
Incubate the reaction for 10 minutes at room temperature.
-
Resuspend the AMPure XP beads by vortexing.
-
Add 40 µl of resuspended AMPure XP beads to the reaction and mix by flicking the tube.
-
Incubate on a Hula mixer (rotator mixer) for 5 minutes at room temperature.
-
Spin down the sample and pellet on a magnet. Keep the tube on the magnet, and pipette off the supernatant when clear and colourless.
-
Wash the beads by adding either 250 μl Long Fragment Buffer (LFB) or 250 μl Short Fragment Buffer (SFB). Flick the beads to resuspend, spin down, then return the tube to the magnetic rack and allow the beads to pellet. Remove the supernatant using a pipette and discard.
-
Repeat the previous step.
-
Spin down and place the tube back on the magnet. Pipette off any residual supernatant. Allow to dry for ~30 seconds, but do not dry the pellet to the point of cracking.
-
Remove the tube from the magnetic rack and resuspend the pellet in 15 µl Elution Buffer (EB). Spin down and incubate for 10 minutes at room temperature. For high molecular weight DNA, incubating at 37°C can improve the recovery of long fragments.
-
Pellet the beads on a magnet until the eluate is clear and colourless, for at least 1 minute.
-
Remove and retain 15 µl of eluate containing the DNA library into a clean 1.5 ml Eppendorf DNA LoBind tube.
Dispose of the pelleted beads
-
Quantify 1 µl of eluted sample using a Qubit fluorometer.
-
Optional ActionIf quantities allow, the library may be diluted in Elution Buffer (EB) for splitting across multiple flow cells.
Additional buffer for doing this can be found in the Sequencing Auxiliary Vials expansion (EXP-AUX001), available to purchase separately. This expansion also contains additional vials of Sequencing Buffer (SQB) and Loading Beads (LB), required for loading the libraries onto flow cells.
Priming and loading the SpotON flow cell
Priming and loading the SpotON flow cell
- Materials
-
- Flow Cell Priming Kit (EXP-FLP002)
- Loading Beads (LB)
- Sequencing Buffer (SQB)
- Consumables
-
- 1.5 ml Eppendorf DNA LoBind tubes
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Equipment
-
- MinION Mk1B or Mk1C
- SpotON Flow Cell
- P1000 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
-
Thaw the Sequencing Buffer (SQB), Loading Beads (LB), Flush Tether (FLT) and one tube of Flush Buffer (FB) at room temperature before mixing the reagents by vortexing, and spin down at room temperature.
-
To prepare the flow cell priming mix, add 30 µl of thawed and mixed Flush Tether (FLT) directly to the tube of thawed and mixed Flush Buffer (FB), and mix by vortexing at room temperature.
-
Open the MinION device lid and slide the flow cell under the clip.
Press down firmly on the flow cell to ensure correct thermal and electrical contact.


-
Optional ActionComplete a flow cell check to assess the number of pores available before loading the library.
This step can be omitted if the flow cell has been checked previously.
See the flow cell check instructions in the MinKNOW protocol for more information.
-
Slide the flow cell priming port cover clockwise to open the priming port.

-
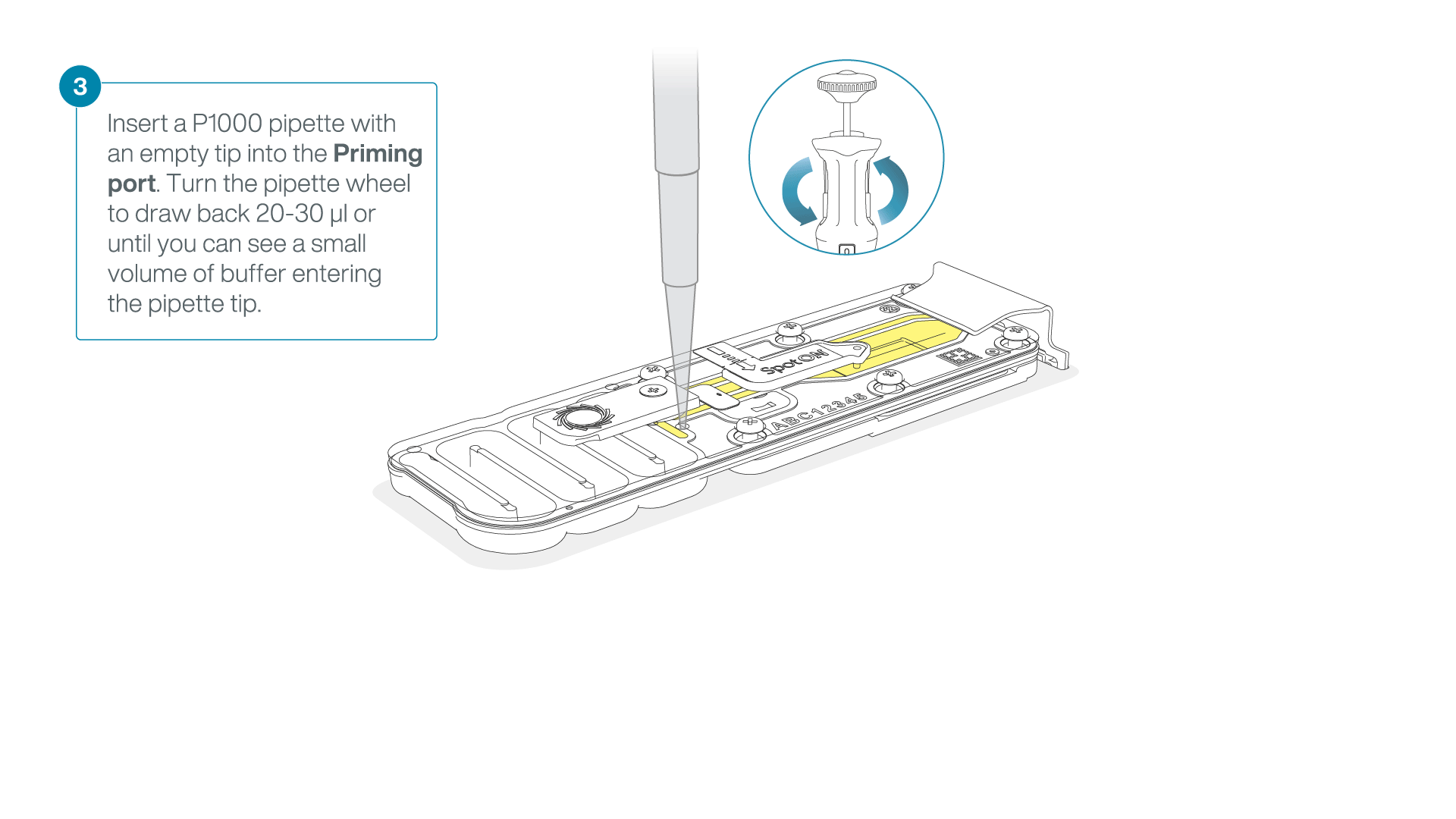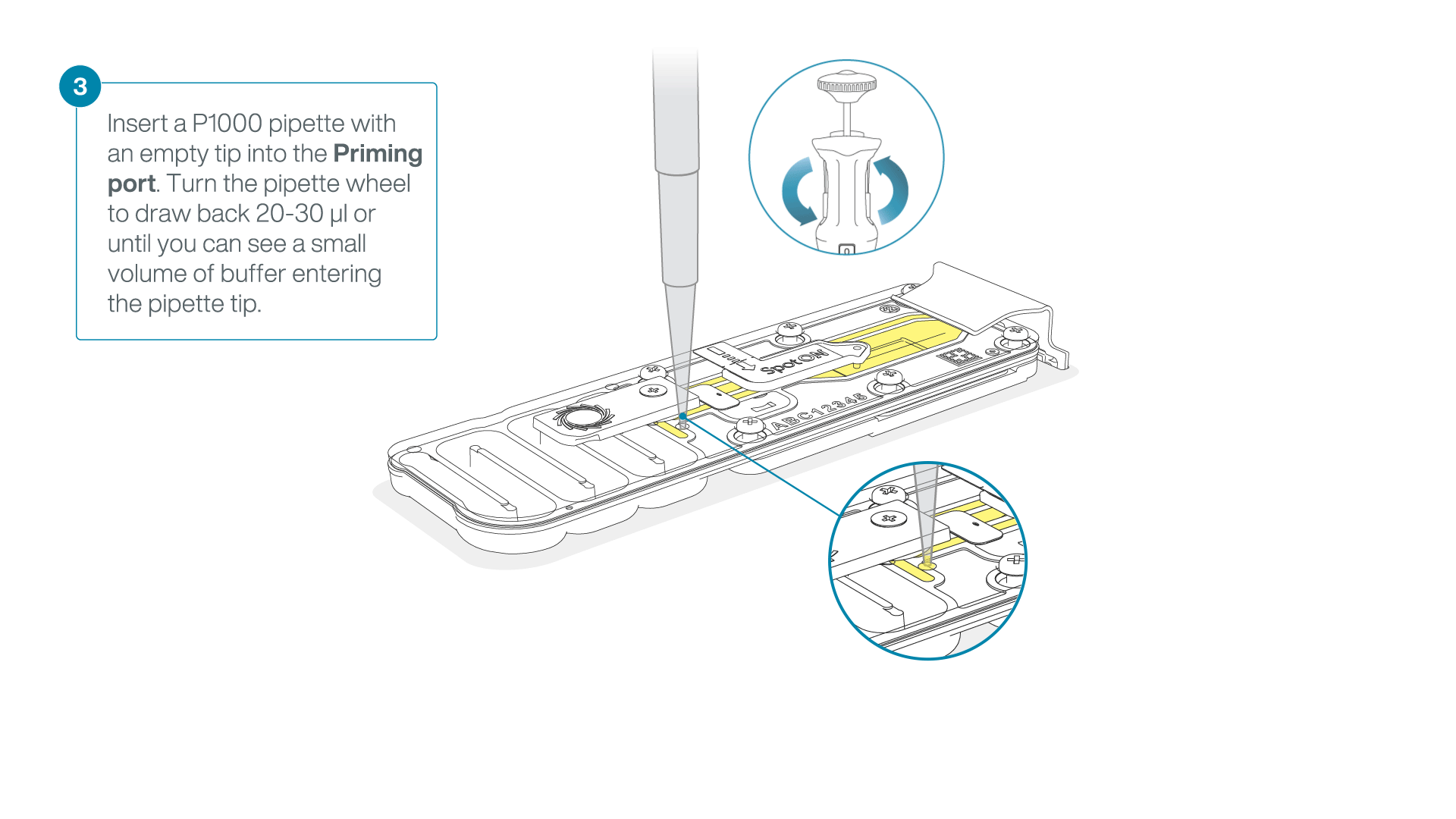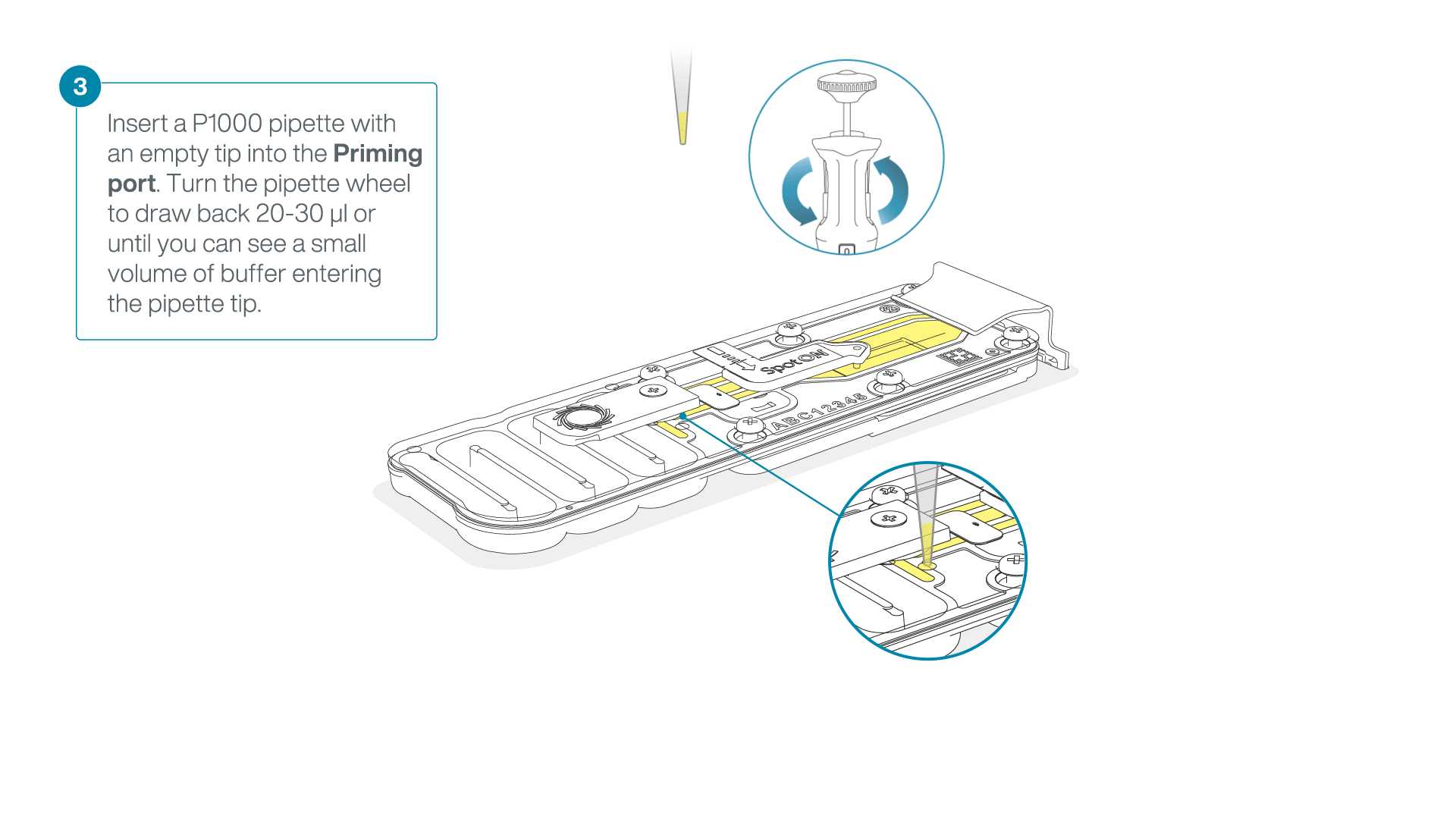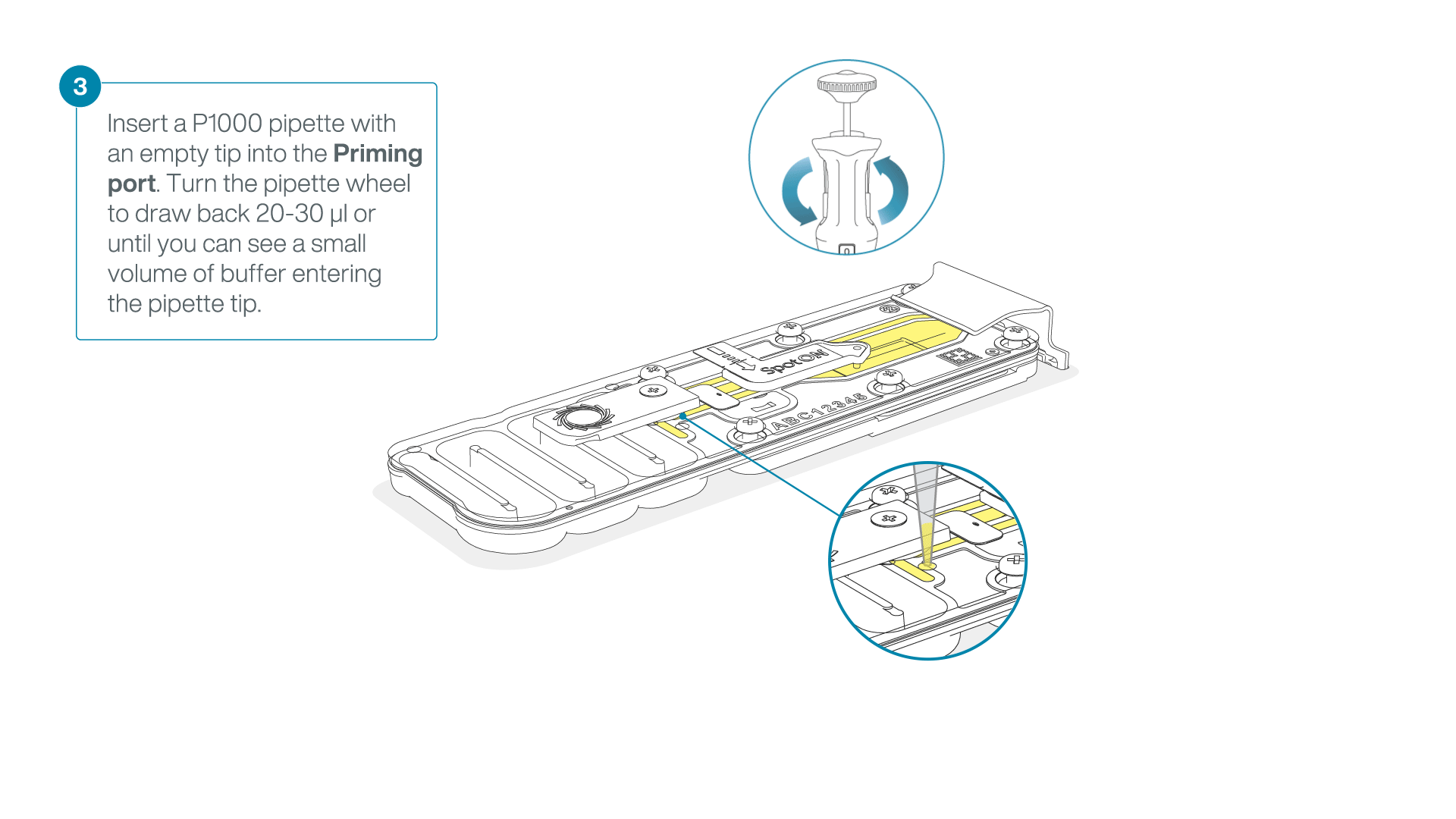
After opening the priming port, check for a small air bubble under the cover. Draw back a small volume to remove any bubbles:
- Set a P1000 pipette to 200 µl
- Insert the tip into the priming port
- Turn the wheel until the dial shows 220-230 µl, to draw back 20-30 µl, or until you can see a small volume of buffer entering the pipette tip
Note: Visually check that there is continuous buffer from the priming port across the sensor array.
-
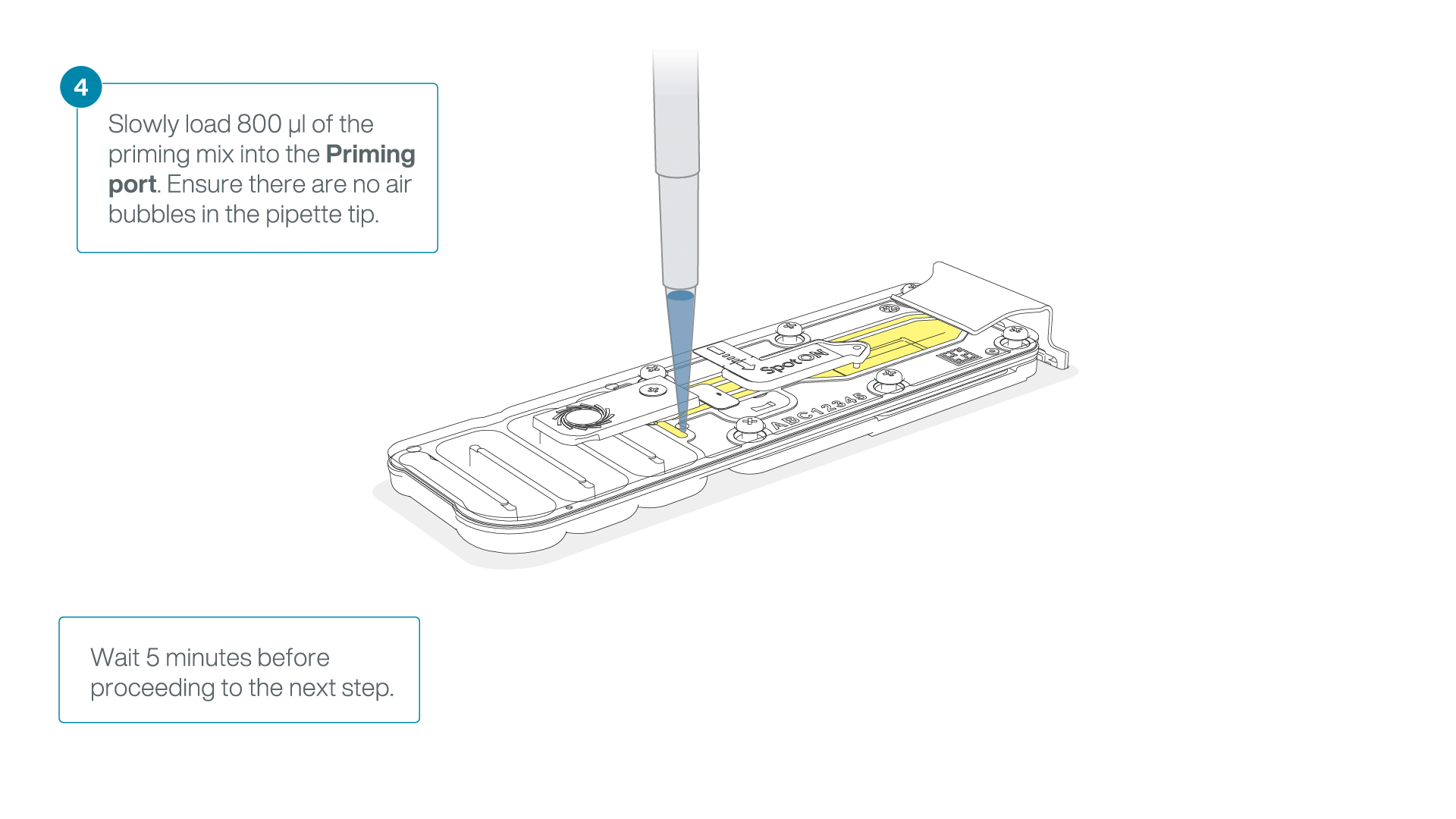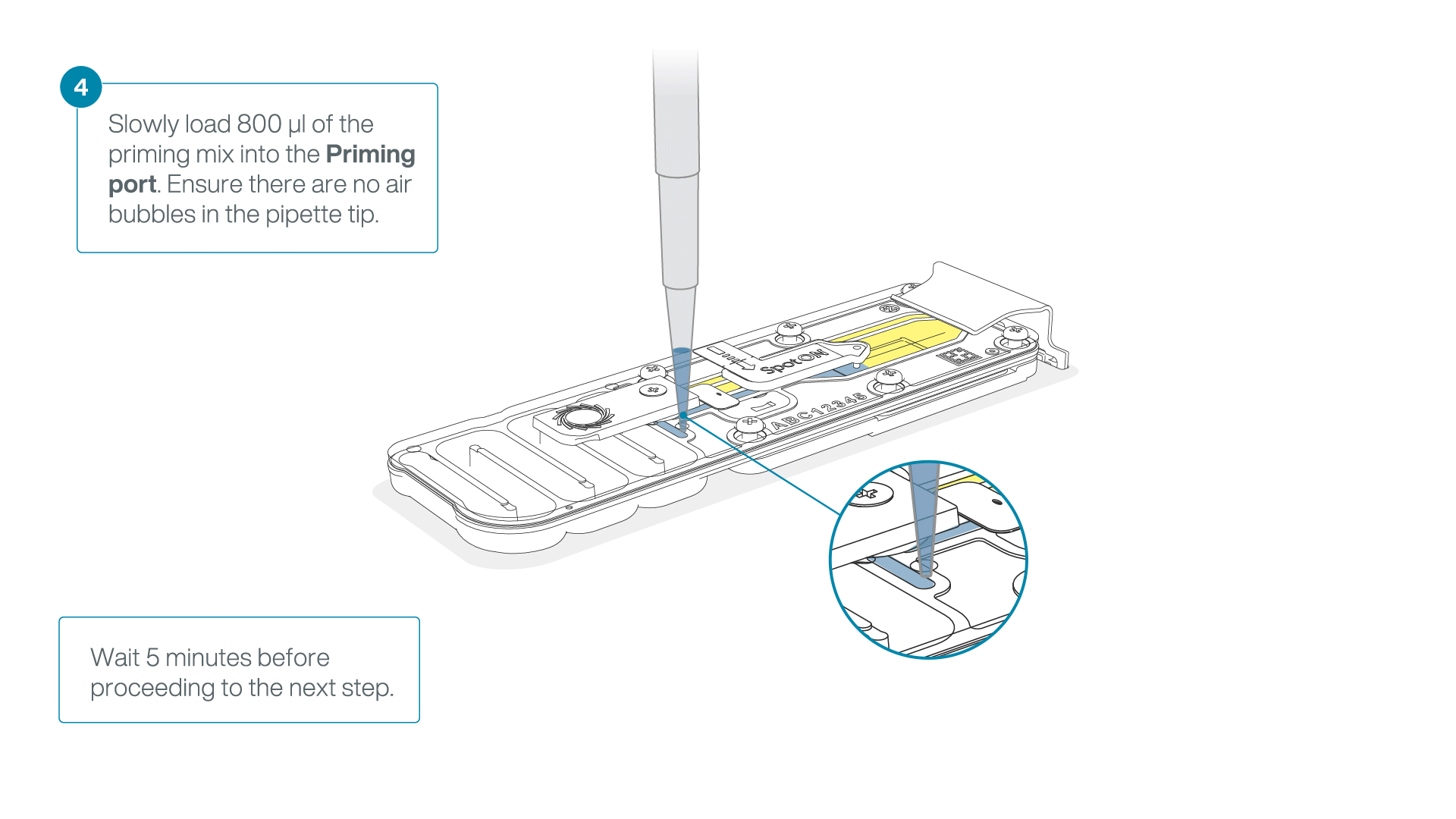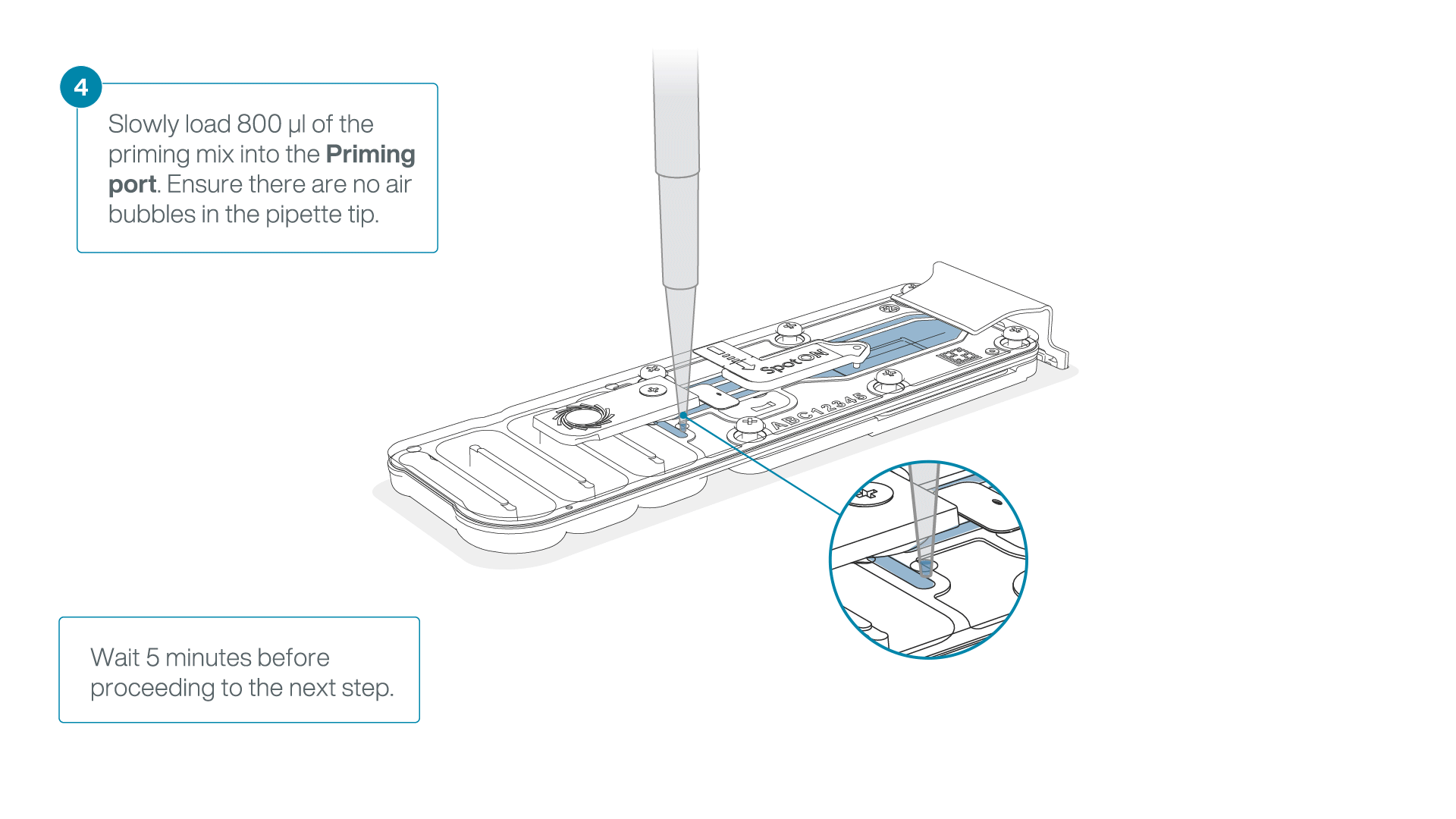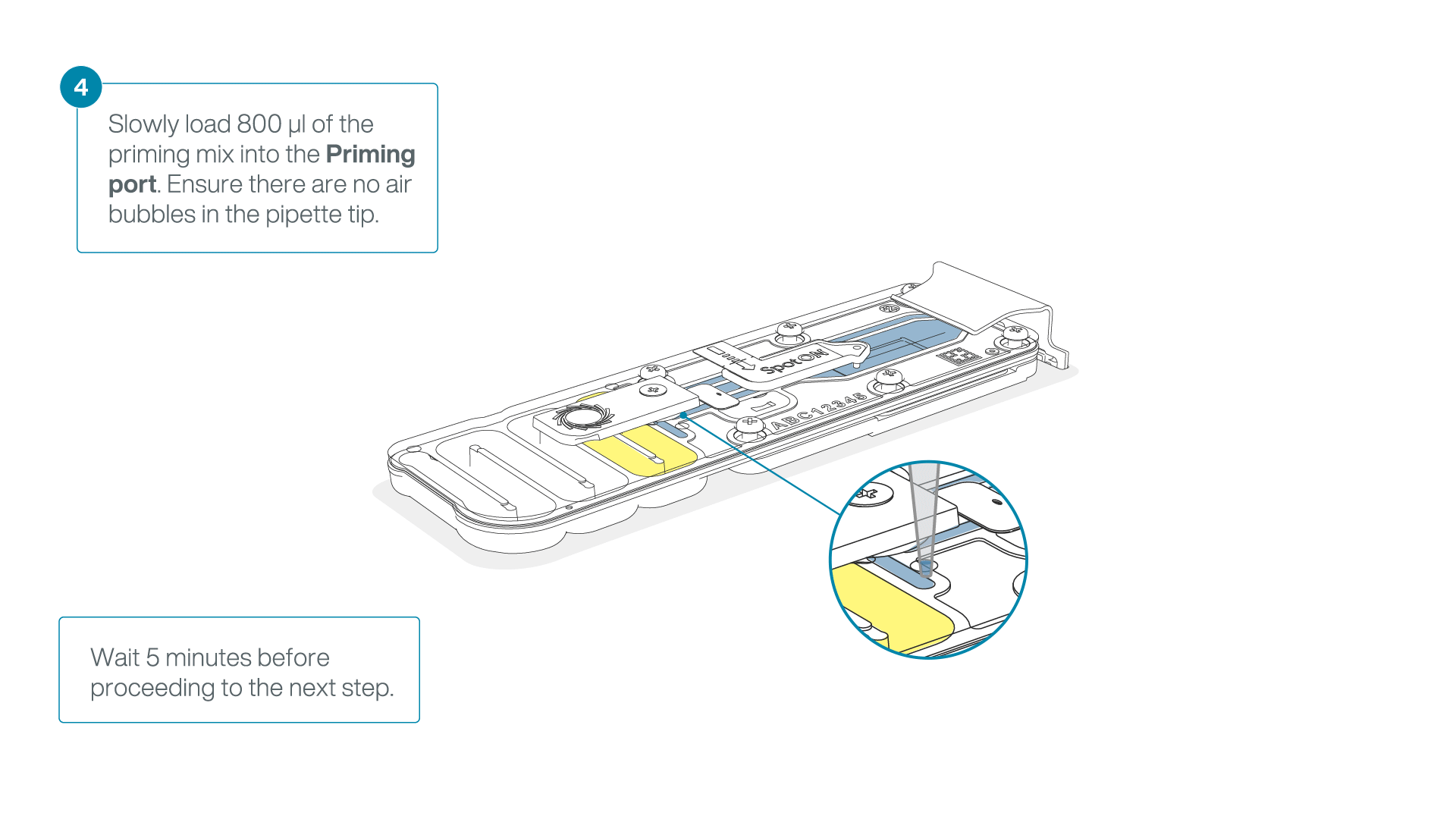
Load 800 µl of the priming mix into the flow cell via the priming port, avoiding the introduction of air bubbles. Wait for five minutes. During this time, prepare the library for loading by following the steps below.
-
Thoroughly mix the contents of the Loading Beads (LB) by pipetting.
-
In a new tube, prepare the library for loading as follows:
Reagent Volume per flow cell Sequencing Buffer (SQB) 37.5 µl Loading Beads (LB), mixed immediately before use 25.5 µl DNA library 12 µl Total 75 µl Note: Load the library onto the flow cell immediately after adding the Sequencing Buffer (SQB) and Loading Beads (LB) because the fuel in the buffer will start to be consumed by the adapter.
-
Complete the flow cell priming:
- Gently lift the SpotON sample port cover to make the SpotON sample port accessible.
- Load 200 µl of the priming mix into the flow cell priming port (not the SpotON sample port), avoiding the introduction of air bubbles.

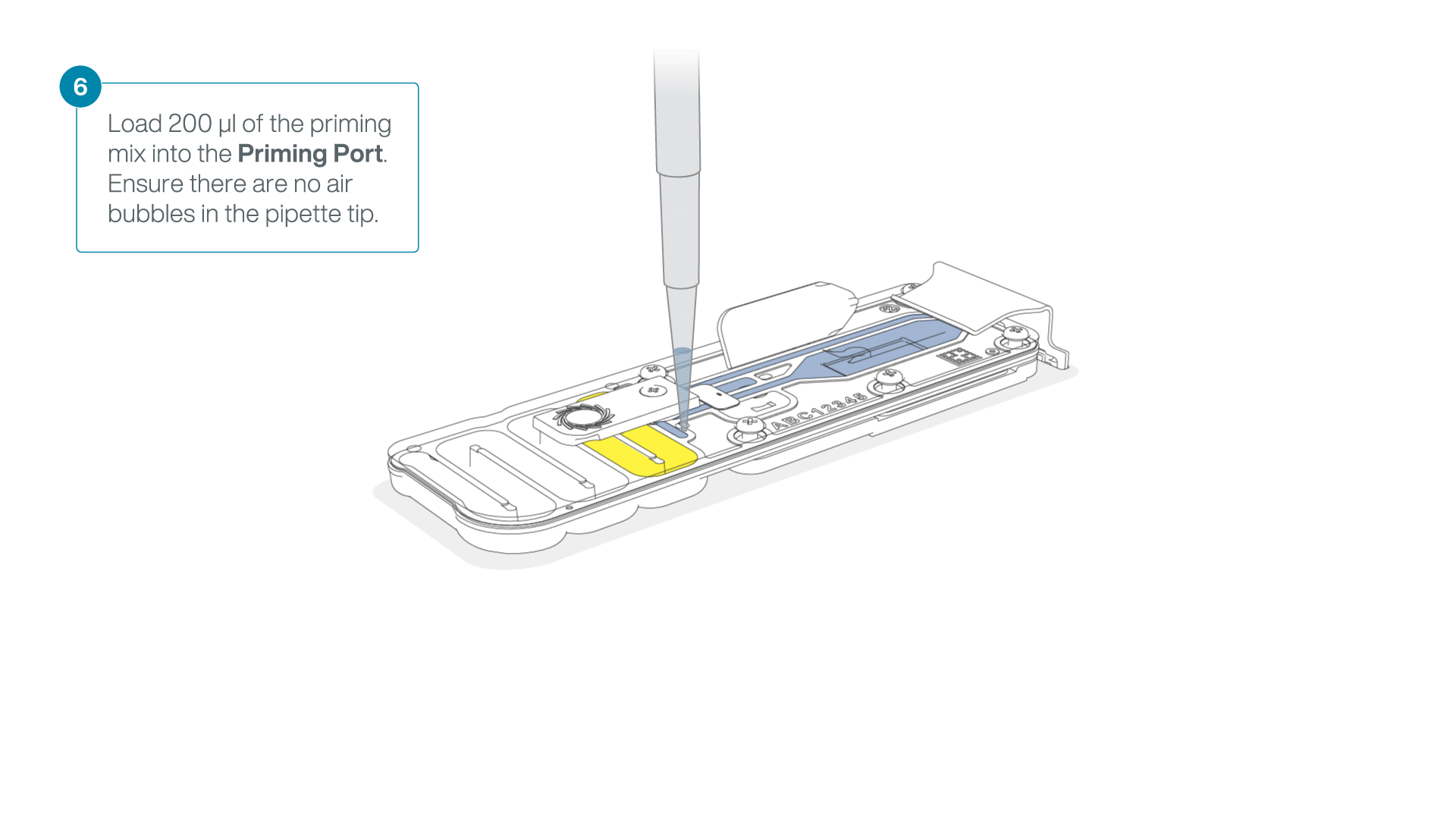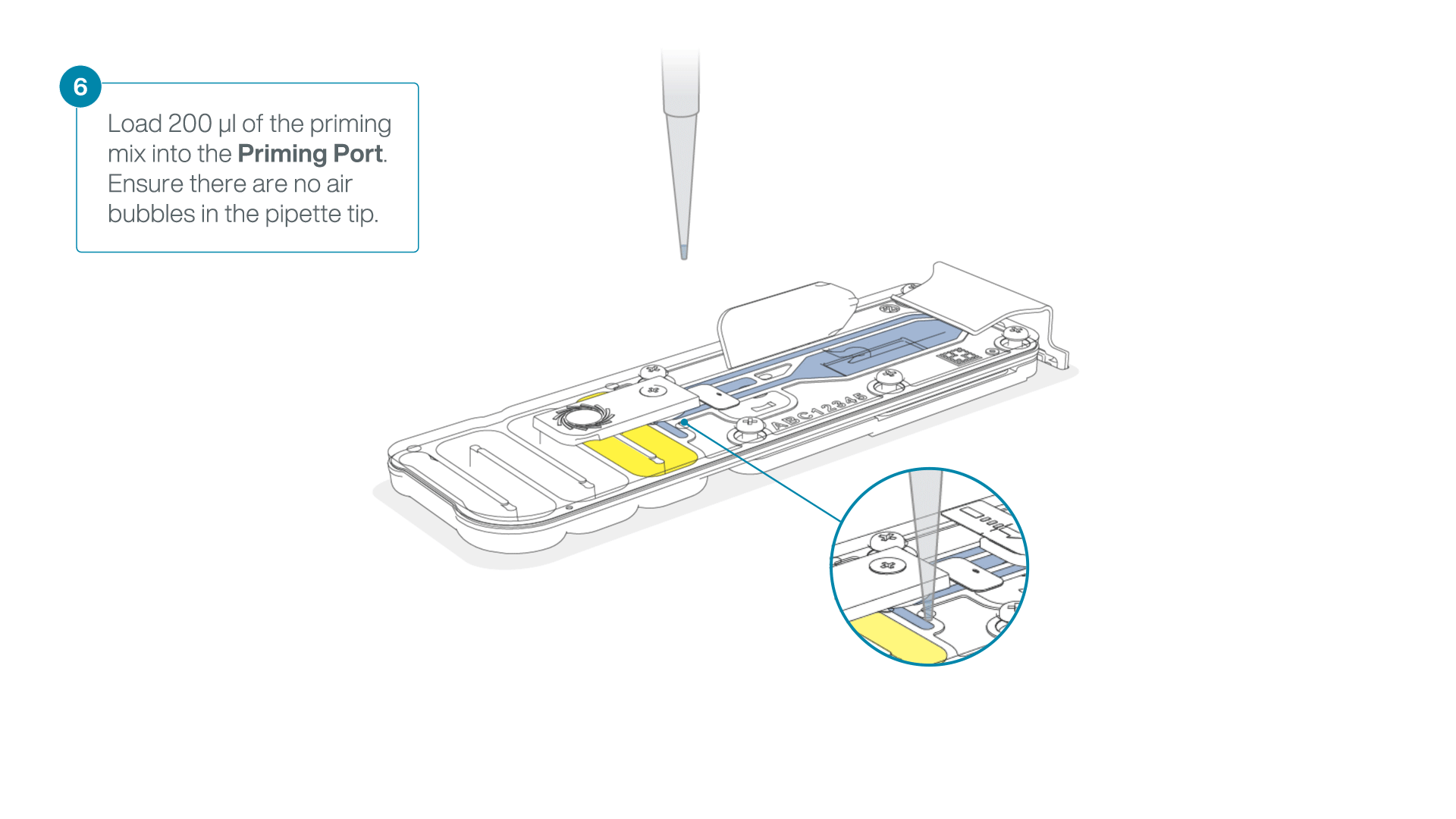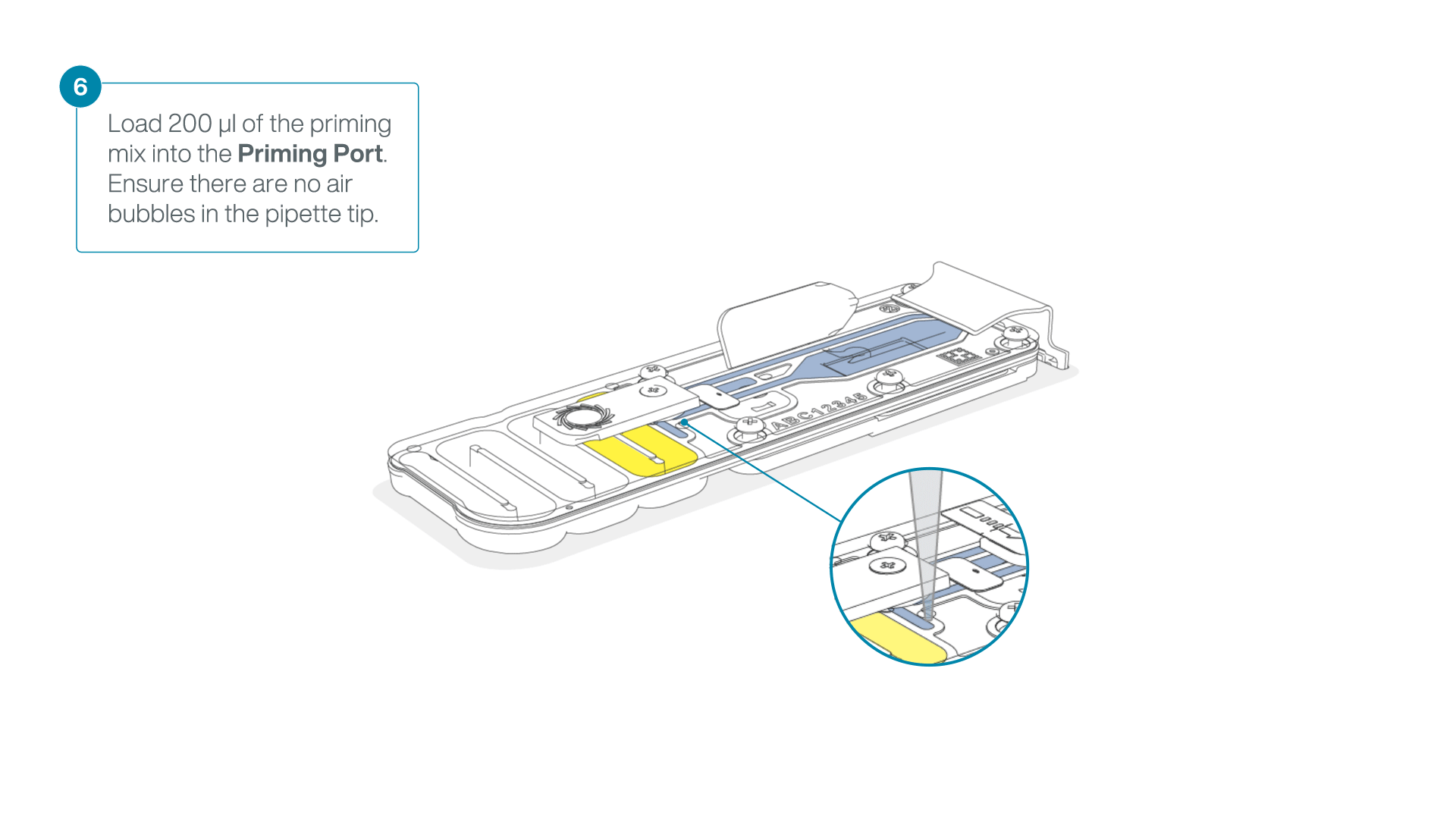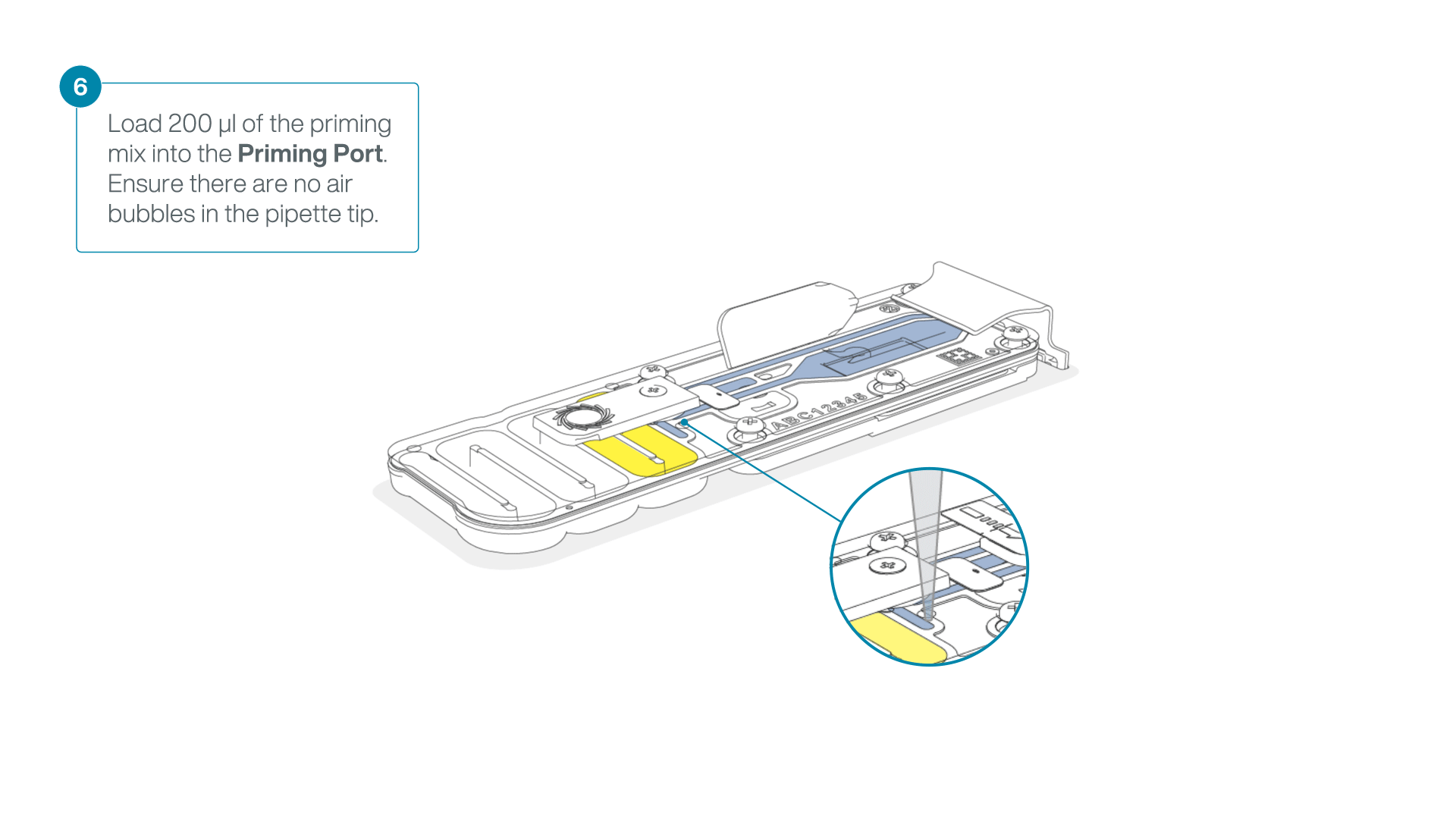
-
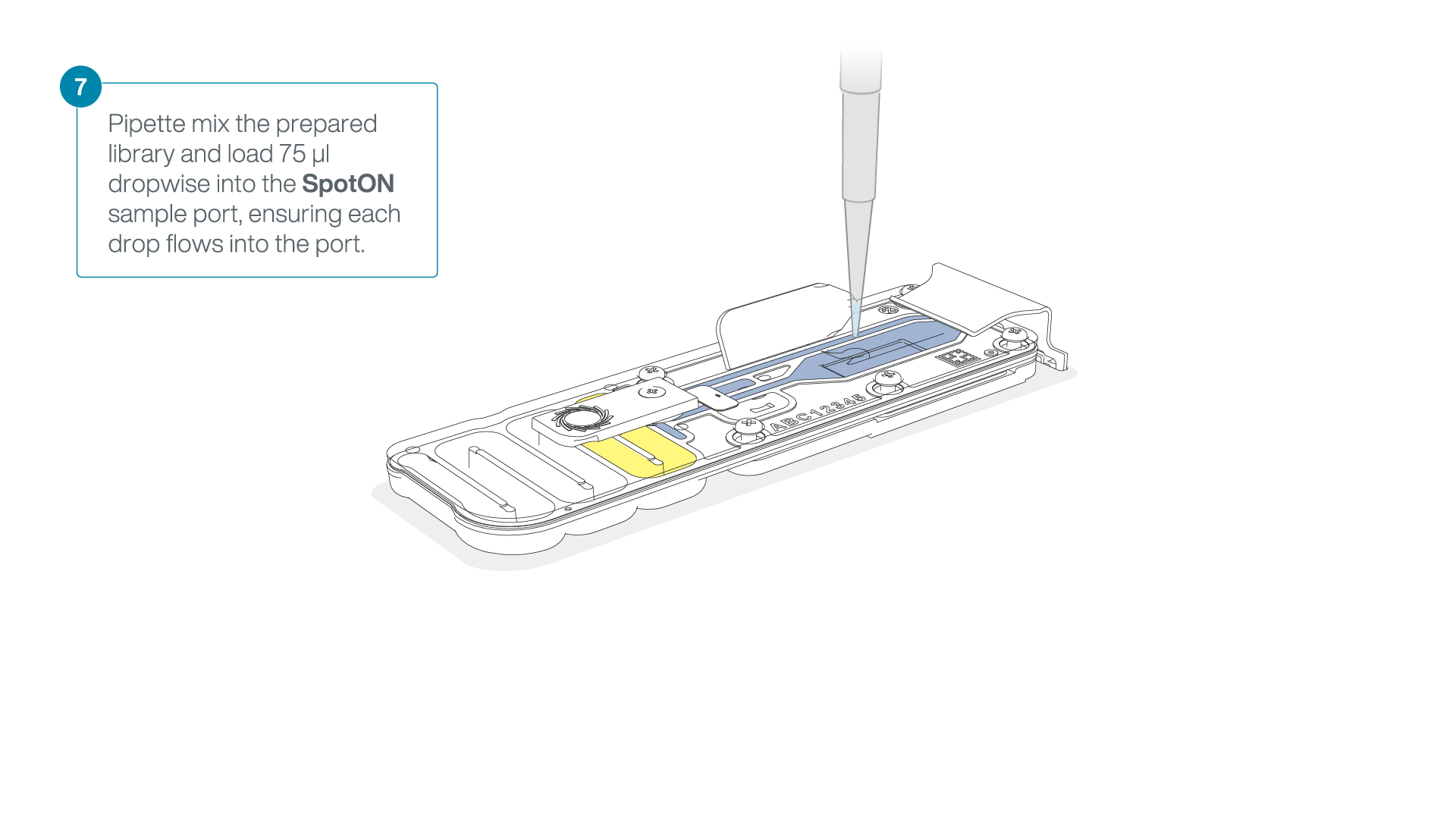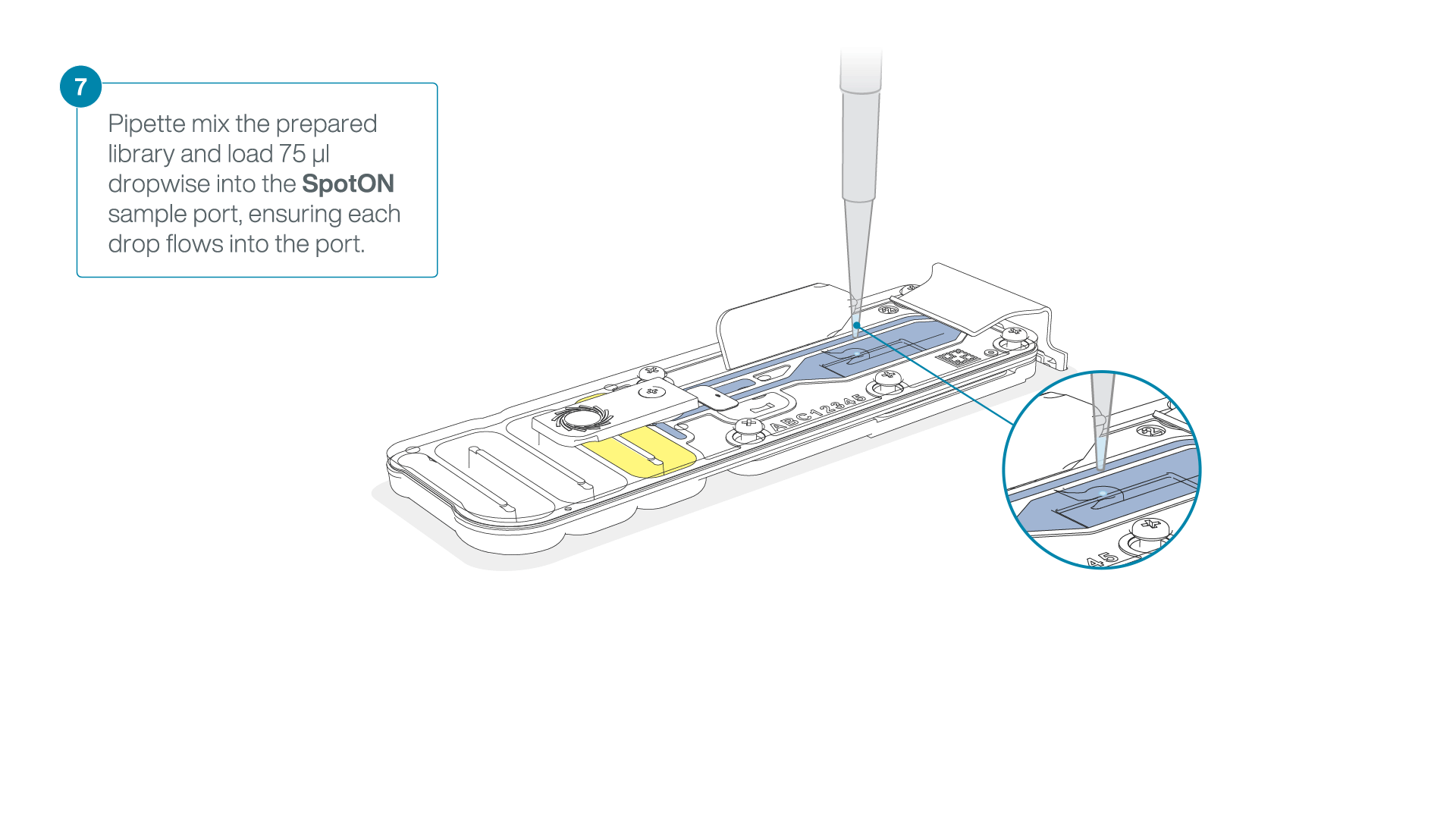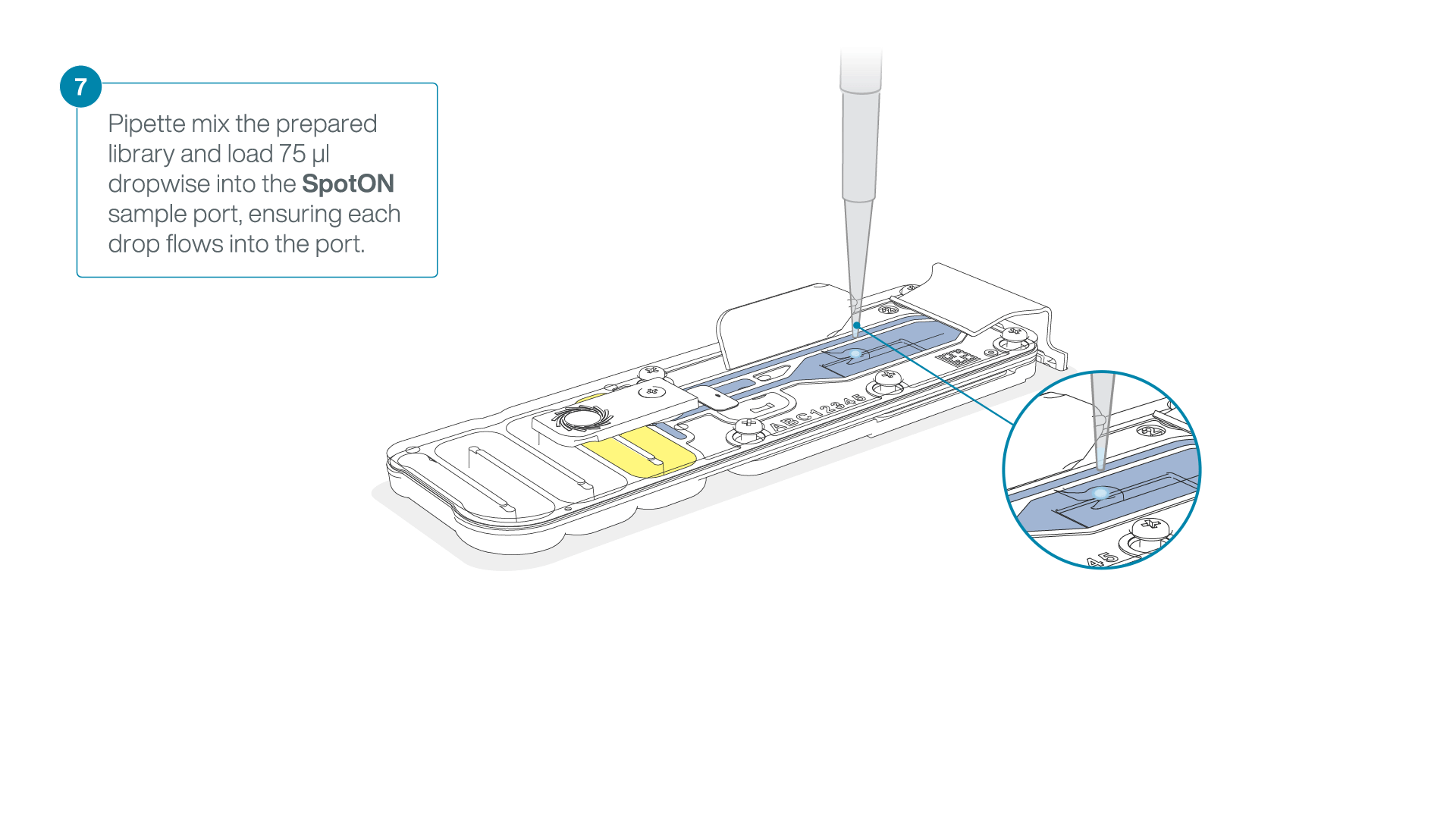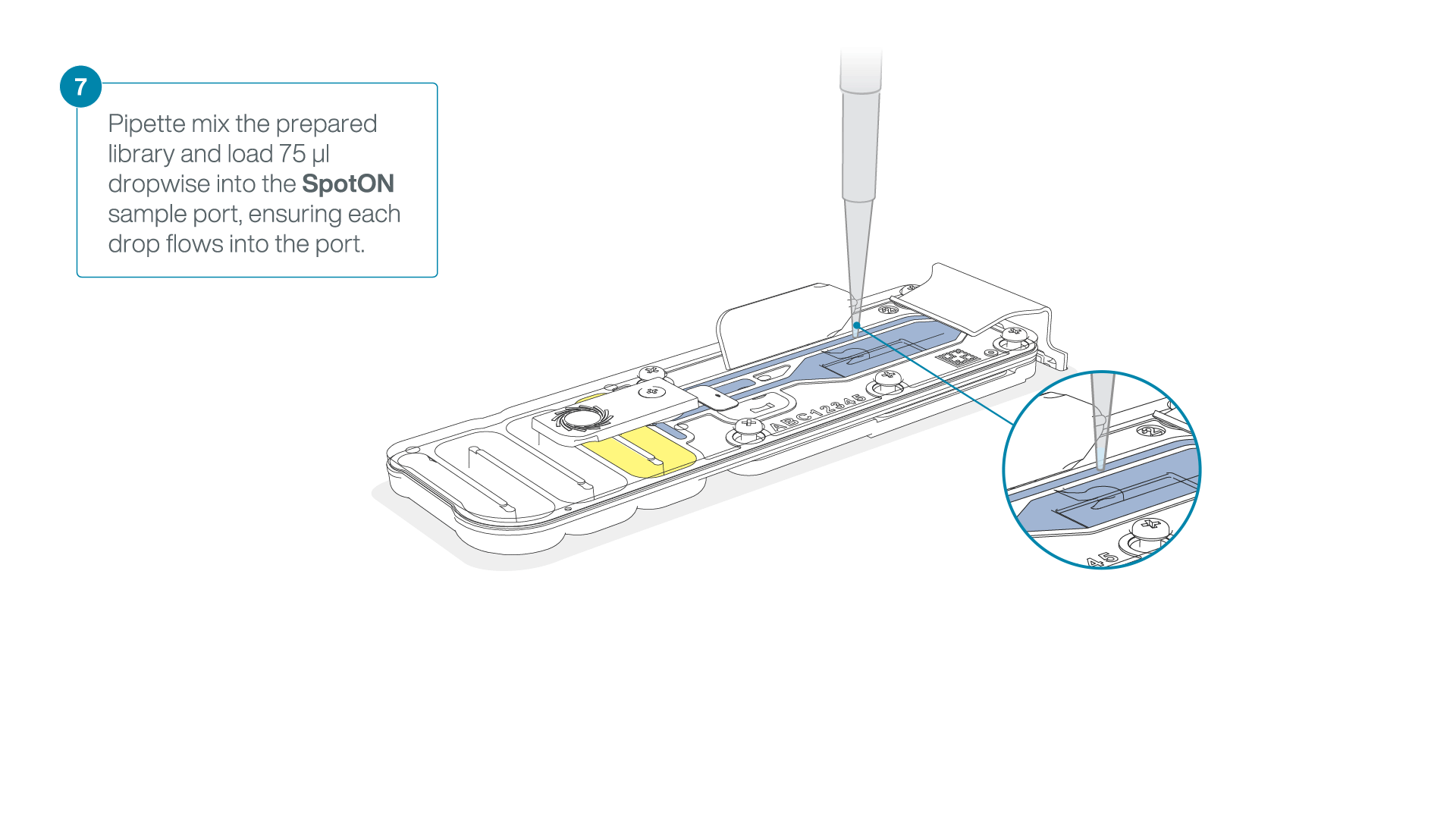
Mix the prepared library gently by pipetting up and down just prior to loading.
-
Add 75 μl of the prepared library to the flow cell via the SpotON sample port in a dropwise fashion. Ensure each drop flows into the port before adding the next.
-
Gently replace the SpotON sample port cover, making sure the bung enters the SpotON port, close the priming port and replace the MinION device lid.












Sequencing and data analysis
Data acquisition and basecalling
Data acquisition and basecalling
-
How to start sequencing
Once you have loaded your flow cell, the sequencing run can be started on MinKNOW, our sequencing software that controls the device, data acquisition and real-time basecalling. For more detailed information on setting up and using MinKNOW, please see the MinKNOW protocol.
MinKNOW can be used and set up to sequence in multiple ways:
- On a computer either directly or remotely connected to a sequencing device.
- Directly on a GridION or PromethION 24/48 sequencing device.
For more information on using MinKNOW on a sequencing device, please see the device user manuals:
- MinION Mk1B user manual
- MinION Mk1C user manual
- MinION Mk1D user manual
- GridION user manual
To start a sequencing run on MinKNOW:
1. Navigate to the start page and click Start sequencing.
2. Fill in your experiment details, such as name and flow cell position and sample ID.
3. Select the sequencing kit used in the library preparation on the Kit page.
4. Configure the sequencing and output parameters for your sequencing run or keep to the default settings on the Run configuration tab.
Note: If basecalling was turned off when a sequencing run was set up, basecalling can be performed post-run on MinKNOW. For more information, please see the MinKNOW protocol.
5. Click Start to initiate the sequencing run.
-
Data analysis after sequencing
After sequencing has completed on MinKNOW, the flow cell can be reused or returned, as outlined in the Flow cell reuse and returns section.
After sequencing and basecalling, the data can be analysed. For further information about options for basecalling and post-basecalling analysis, please refer to the Data Analysis document.
In the Downstream analysis section, we outline further options for analysing your data.
Flow cell reuse and returns
Flow cell reuse and returns
- Materials
-
- Flow Cell Wash Kit (EXP-WSH004)
-
After your sequencing experiment is complete, if you would like to reuse the flow cell, please follow the Flow Cell Wash Kit protocol and store the washed flow cell at +2°C to +8°C.
The Flow Cell Wash Kit protocol is available on the Nanopore Community.
-
Alternatively, follow the returns procedure to send the flow cell back to Oxford Nanopore.
Instructions for returning flow cells can be found here.
Downstream analysis
Downstream analysis
-
Post-basecalling analysis
There are several options for further analysing your basecalled data:
1. EPI2ME workflows
For in-depth data analysis, Oxford Nanopore Technologies offers a range of bioinformatics tutorials and workflows available in EPI2ME. The platform provides a vehicle where workflows deposited in GitHub by our Research and Applications teams can be showcased with descriptive texts, functional bioinformatics code and example data.
2. Research analysis tools
Oxford Nanopore Technologies' Research division has created a number of analysis tools, which are available in the Oxford Nanopore GitHub repository. The tools are aimed at advanced users, and contain instructions for how to install and run the software. They are provided as-is, with minimal support.
3. Community-developed analysis tools
If a data analysis method for your research question is not provided in any of the resources above, please refer to the resource centre and search for bioinformatics tools for your application. Numerous members of the Nanopore Community have developed their own tools and pipelines for analysing nanopore sequencing data, most of which are available on GitHub. Please be aware that these tools are not supported by Oxford Nanopore Technologies, and are not guaranteed to be compatible with the latest chemistry/software configuration.
Troubleshooting
Issues during DNA/RNA extraction and library preparation
Issues during DNA/RNA extraction and library preparation
-
Below is a list of the most commonly encountered issues, with some suggested causes and solutions.
We also have an FAQ section available on the Nanopore Community Support section.
If you have tried our suggested solutions and the issue still persists, please contact Technical Support via email (support@nanoporetech.com) or via LiveChat in the Nanopore Community.
-
Low sample quality
Observation Possible cause Comments and actions Low DNA purity (Nanodrop reading for DNA OD 260/280 is <1.8 and OD 260/230 is <2.0–2.2) The DNA extraction method does not provide the required purity The effects of contaminants are shown in the Contaminants document. Please try an alternative extraction method that does not result in contaminant carryover.
Consider performing an additional SPRI clean-up step.Low RNA integrity (RNA integrity number <9.5 RIN, or the rRNA band is shown as a smear on the gel) The RNA degraded during extraction Try a different RNA extraction method. For more info on RIN, please see the RNA Integrity Number document. Further information can be found in the DNA/RNA Handling page. RNA has a shorter than expected fragment length The RNA degraded during extraction Try a different RNA extraction method. For more info on RIN, please see the RNA Integrity Number document. Further information can be found in the DNA/RNA Handling page.
We recommend working in an RNase-free environment, and to keep your lab equipment RNase-free when working with RNA. -
Low DNA recovery after AMPure bead clean-up
Observation Possible cause Comments and actions Low recovery DNA loss due to a lower than intended AMPure beads-to-sample ratio 1. AMPure beads settle quickly, so ensure they are well resuspended before adding them to the sample.
2. When the AMPure beads-to-sample ratio is lower than 0.4:1, DNA fragments of any size will be lost during the clean-up.Low recovery DNA fragments are shorter than expected The lower the AMPure beads-to-sample ratio, the more stringent the selection against short fragments. Please always determine the input DNA length on an agarose gel (or other gel electrophoresis methods) and then calculate the appropriate amount of AMPure beads to use. 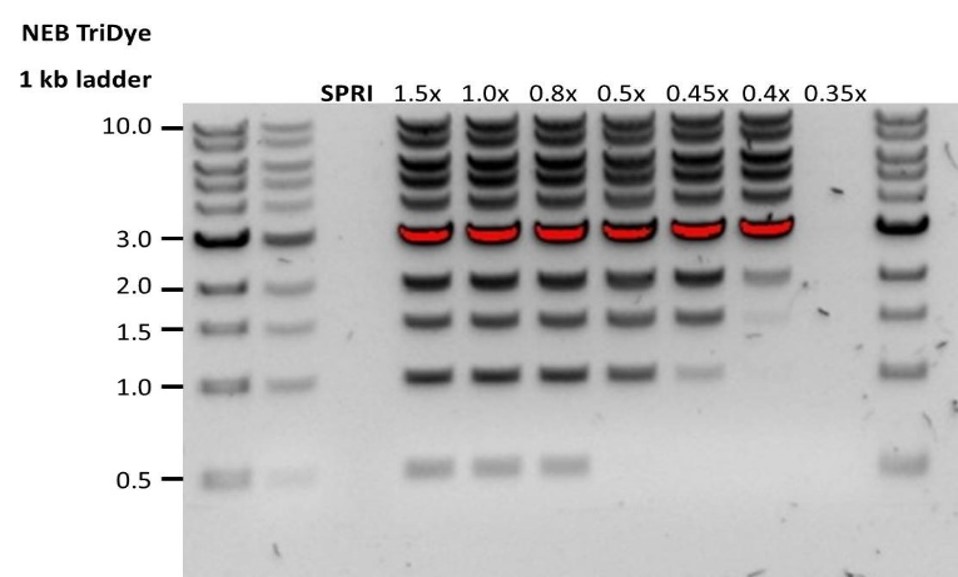
Low recovery after end-prep The wash step used ethanol <70% DNA will be eluted from the beads when using ethanol <70%. Make sure to use the correct percentage.

Issues during the sequencing run
Issues during the sequencing run
-
Below is a list of the most commonly encountered issues, with some suggested causes and solutions.
We also have an FAQ section available on the Nanopore Community Support section.
If you have tried our suggested solutions and the issue still persists, please contact Technical Support via email (support@nanoporetech.com) or via LiveChat in the Nanopore Community.
-
Fewer pores at the start of sequencing than after Flow Cell Check
Observation Possible cause Comments and actions MinKNOW reported a lower number of pores at the start of sequencing than the number reported by the Flow Cell Check An air bubble was introduced into the nanopore array After the Flow Cell Check it is essential to remove any air bubbles near the priming port before priming the flow cell. If not removed, the air bubble can travel to the nanopore array and irreversibly damage the nanopores that have been exposed to air. The best practice to prevent this from happening is demonstrated in this video. MinKNOW reported a lower number of pores at the start of sequencing than the number reported by the Flow Cell Check The flow cell is not correctly inserted into the device Stop the sequencing run, remove the flow cell from the sequencing device and insert it again, checking that the flow cell is firmly seated in the device and that it has reached the target temperature. If applicable, try a different position on the device (GridION/PromethION). MinKNOW reported a lower number of pores at the start of sequencing than the number reported by the Flow Cell Check Contaminations in the library damaged or blocked the pores The pore count during the Flow Cell Check is performed using the QC DNA molecules present in the flow cell storage buffer. At the start of sequencing, the library itself is used to estimate the number of active pores. Because of this, variability of about 10% in the number of pores is expected. A significantly lower pore count reported at the start of sequencing can be due to contaminants in the library that have damaged the membranes or blocked the pores. Alternative DNA/RNA extraction or purification methods may be needed to improve the purity of the input material. The effects of contaminants are shown in the Contaminants Know-how piece. Please try an alternative extraction method that does not result in contaminant carryover. -
MinKNOW script failed
Observation Possible cause Comments and actions MinKNOW shows "Script failed" Restart the computer and then restart MinKNOW. If the issue persists, please collect the MinKNOW log files and contact Technical Support. If you do not have another sequencing device available, we recommend storing the flow cell and the loaded library at 4°C and contact Technical Support for further storage guidance. -
Pore occupancy below 40%
Observation Possible cause Comments and actions Pore occupancy <40% Not enough library was loaded on the flow cell Ensure you load the recommended amount of good quality library in the relevant library prep protocol onto your flow cell. Please quantify the library before loading and calculate mols using tools like the Promega Biomath Calculator, choosing "dsDNA: µg to pmol" Pore occupancy close to 0 The Ligation Sequencing Kit was used, and sequencing adapters did not ligate to the DNA Make sure to use the NEBNext Quick Ligation Module (E6056) and Oxford Nanopore Technologies Ligation Buffer (LNB, provided in the sequencing kit) at the sequencing adapter ligation step, and use the correct amount of each reagent. A Lambda control library can be prepared to test the integrity of the third-party reagents. Pore occupancy close to 0 The Ligation Sequencing Kit was used, and ethanol was used instead of LFB or SFB at the wash step after sequencing adapter ligation Ethanol can denature the motor protein on the sequencing adapters. Make sure the LFB or SFB buffer was used after ligation of sequencing adapters. Pore occupancy close to 0 No tether on the flow cell Tethers are adding during flow cell priming (FLT/FCT tube). Make sure FLT/FCT was added to FB/FCF before priming. -
Shorter than expected read length
Observation Possible cause Comments and actions Shorter than expected read length Unwanted fragmentation of DNA sample Read length reflects input DNA fragment length. Input DNA can be fragmented during extraction and library prep.
1. Please review the Extraction Methods in the Nanopore Community for best practice for extraction.
2. Visualise the input DNA fragment length distribution on an agarose gel before proceeding to the library prep.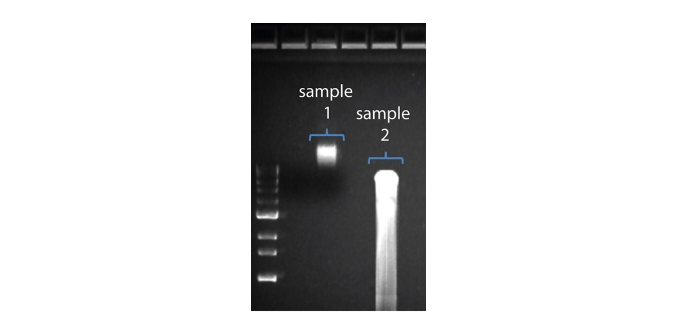 In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented.
In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented.
3. During library prep, avoid pipetting and vortexing when mixing reagents. Flicking or inverting the tube is sufficient. -
Large proportion of unavailable pores
Observation Possible cause Comments and actions Large proportion of unavailable pores (shown as blue in the channels panel and pore activity plot) 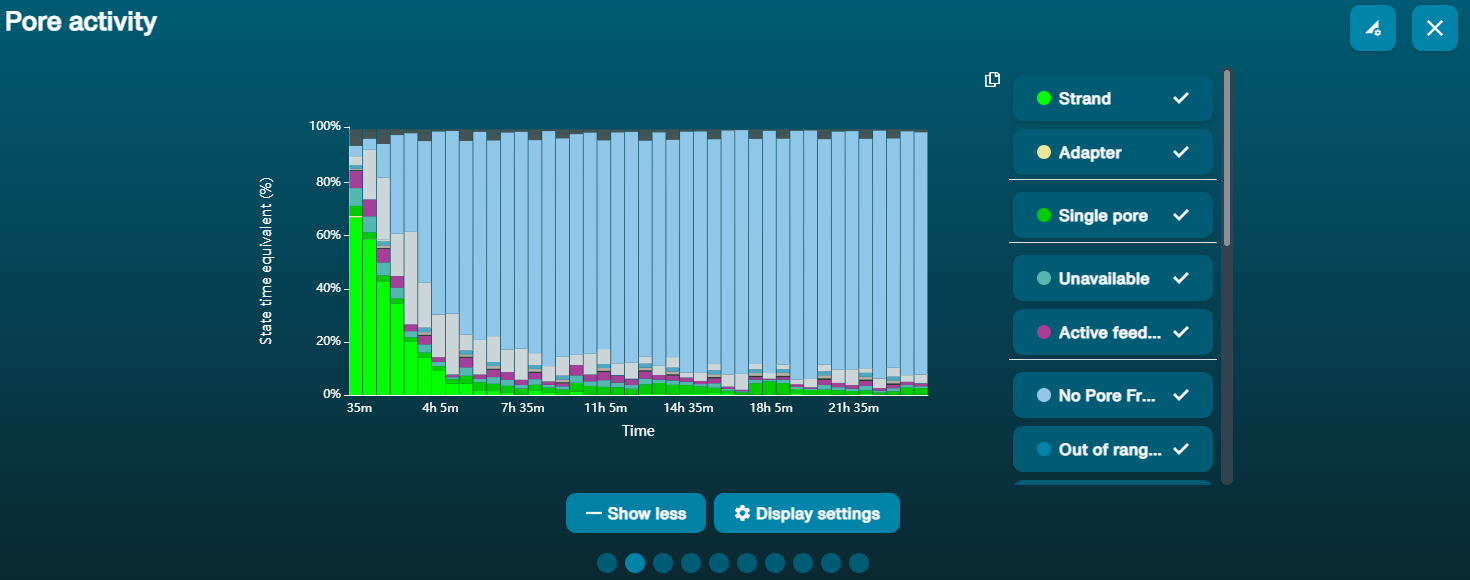 The pore activity plot above shows an increasing proportion of "unavailable" pores over time.
The pore activity plot above shows an increasing proportion of "unavailable" pores over time.Contaminants are present in the sample Some contaminants can be cleared from the pores by the unblocking function built into MinKNOW. If this is successful, the pore status will change to "sequencing pore". If the portion of unavailable pores stays large or increases:
1. A nuclease flush using the Flow Cell Wash Kit (EXP-WSH004) can be performed, or
2. Run several cycles of PCR to try and dilute any contaminants that may be causing problems. -
Large proportion of inactive pores
Observation Possible cause Comments and actions Large proportion of inactive/unavailable pores (shown as light blue in the channels panel and pore activity plot. Pores or membranes are irreversibly damaged) Air bubbles have been introduced into the flow cell Air bubbles introduced through flow cell priming and library loading can irreversibly damage the pores. Watch the Priming and loading your flow cell video for best practice Large proportion of inactive/unavailable pores Certain compounds co-purified with DNA Known compounds, include polysaccharides, typically associate with plant genomic DNA.
1. Please refer to the Plant leaf DNA extraction method.
2. Clean-up using the QIAGEN PowerClean Pro kit.
3. Perform a whole genome amplification with the original gDNA sample using the QIAGEN REPLI-g kit.Large proportion of inactive/unavailable pores Contaminants are present in the sample The effects of contaminants are shown in the Contaminants Know-how piece. Please try an alternative extraction method that does not result in contaminant carryover. -
Reduction in sequencing speed and q-score later into the run
Observation Possible cause Comments and actions Reduction in sequencing speed and q-score later into the run For Kit 9 chemistry (e.g. SQK-LSK109), fast fuel consumption is typically seen when the flow cell is overloaded with library (please see the appropriate protocol for your DNA library to see the recommendation). Add more fuel to the flow cell by following the instructions in the MinKNOW protocol. In future experiments, load lower amounts of library to the flow cell. -
Temperature fluctuation
Observation Possible cause Comments and actions Temperature fluctuation The flow cell has lost contact with the device Check that there is a heat pad covering the metal plate on the back of the flow cell. Re-insert the flow cell and press it down to make sure the connector pins are firmly in contact with the device. If the problem persists, please contact Technical Services. -
Failed to reach target temperature
Observation Possible cause Comments and actions MinKNOW shows "Failed to reach target temperature" The instrument was placed in a location that is colder than normal room temperature, or a location with poor ventilation (which leads to the flow cells overheating) MinKNOW has a default timeframe for the flow cell to reach the target temperature. Once the timeframe is exceeded, an error message will appear and the sequencing experiment will continue. However, sequencing at an incorrect temperature may lead to a decrease in throughput and lower q-scores. Please adjust the location of the sequencing device to ensure that it is placed at room temperature with good ventilation, then re-start the process in MinKNOW. Please refer to this link for more information on MinION temperature control. -
Guppy – no input .fast5 was found or basecalled
Observation Possible cause Comments and actions No input .fast5 was found or basecalled input_path did not point to the .fast5 file location The --input_path has to be followed by the full file path to the .fast5 files to be basecalled, and the location has to be accessible either locally or remotely through SSH. No input .fast5 was found or basecalled The .fast5 files were in a subfolder at the input_path location To allow Guppy to look into subfolders, add the --recursive flag to the command -
Guppy – no Pass or Fail folders were generated after basecalling
Observation Possible cause Comments and actions No Pass or Fail folders were generated after basecalling The --qscore_filtering flag was not included in the command The --qscore_filtering flag enables filtering of reads into Pass and Fail folders inside the output folder, based on their strand q-score. When performing live basecalling in MinKNOW, a q-score of 7 (corresponding to a basecall accuracy of ~80%) is used to separate reads into Pass and Fail folders. -
Guppy – unusually slow processing on a GPU computer
Observation Possible cause Comments and actions Unusually slow processing on a GPU computer The --device flag wasn't included in the command The --device flag specifies a GPU device to use for accelerate basecalling. If not included in the command, GPU will not be used. GPUs are counted from zero. An example is --device cuda:0 cuda:1, when 2 GPUs are specified to use by the Guppy command.
 In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented.
In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented. The pore activity plot above shows an increasing proportion of "unavailable" pores over time.
The pore activity plot above shows an increasing proportion of "unavailable" pores over time.Become a full member
Purchase a MinION Starter Pack from Avantor to get full community access and benefit from:
- News - hear about the latest product updates
- Posts - interact with thousands of nanopore users from around the globe
- Software - download the latest sequencing and analysis software
Already have a Nanopore Community account?
Log in hereNeed more help?
Request a call with our experts for detailed advice on implementing nanopore sequencing.
Request a callInterested in microbiology?
Visit our microbial sequencing spotlight page on vwr.com.
Microbial sequencing