Welcome to the Nanopore Community
Order MinION devices and consumables
Visit vwr.comPCR tiling of SARS-CoV-2 virus - automated Hamilton NGS STAR 96 (SQK-LSK109 with EXP-NBD196)
Version for device: MinION
Introduction to the protocol
Overview of the protocol
-
Introduction to the protocol
To enable the support for the rapidly expanding user requests, the team at Oxford Nanopore Technologies have put together a partially automated end-to-end workflow based on the ARTIC Network protocols and analysis methods.
We have developed this automated protocol on the Hamilton NGS Star 96 liquid handling robot. The protocol begins with manual preparation of the RNA samples, which includes reverse transcription and tiled PCR. The remainder of the library preparation is automated with minimal hands-on time which is required for sample quantification and deck re-loading.
While this protocol is available in the Nanopore Community, we kindly ask users to ensure they are citing the members of the ARTIC network who have been behind the development of these methods.
This protocol is based on the ARTIC amplicon sequencing protocol for MinION for nCoV-2019 by Josh Quick. The protocol generates 400 bp amplicons in a tiled fashion across the whole SARS-CoV-2 genome. Some example data is shown in the Downstream analysis and expected results section, this is generated using human coronavirus 229E to show what would be expected when running this protocol with SARS-CoV-2 samples.
Primers were designed by Josh Quick using Primal Scheme; the primer sequences can be found here.
Steps in the sequencing workflow:
Prepare for your experiment
you will need to:- Extract your RNA
- Ensure you have your sequencing kit, the correct equipment and third-party reagents
- Download the software for acquiring and analysing your data
- Check your flow cell to ensure it has enough pores for a good sequencing run
Prepare your library
You will need to:Off-deck:
- Reverse transcribe your RNA samples with random hexamers
- Amplify the samples by tiled PCR using separate primer pools
- Combine the primer pools
Note: On the Hamilton software, each step of the protocol is set up as a process. Currently, the off-deck section comprises Processes 1-2.
On-deck:
- Process 3: Purify and quantify the PCR products
- Processes 4-8: Prepare the DNA ends for adapter attachment and ligate the native barcodes supplied in the kit to the DNA ends and pool the samples
- Processes 10-11: Ligate the sequencing adapters supplied in the kit to the DNA ends
Off-deck:
- Prime the flow cell and load your DNA library into the flow cell

Note: Timings are dependent on number of samples and include hands on time, such as deck loading and sample quantificationSequencing and analysis
You will need to:- Start a sequencing run using the MinKNOW software, which will collect raw data from the device and convert it into basecalled reads
- Start the EPI2ME software and select the barcoding workflow
-
Timings
Off-deck library preparation:
Process X96 samples Reverse transcription ~20 minutes PCR tiling ~260 minutes Note: Manual preparation timings are for X96 samples. However, PCR tiling can take between ~200-260 minutes depending on the number of samples prepared.
On-deck library preparation:
Process X24 samples X48 samples X96 samples Hands-on time Deck set-up ~30 minutes Process 3:
PCR tiling clean-up~53 minutes ~60 minutes ~60 minutes Quantification ~20 minutes Deck loading ~30 minutes Processes 4-8:
End-prep and native barcode ligation~200 minutes ~240 minutes ~280 minutes Quantification ~10 minutes Deck loading ~30 minutes Processes 10-11:
Adapter ligation and clean-up~90 minutes ~90 minutes ~90 minutes Quantification ~10 minutes Total 5 hours 43 minutes 6 hours 30 minutes 7 hours 2 hours 10 minutes -
Before starting
This protocol requires total RNA extracted from samples that have been screened by a suitable qPCR assay. Here we demonstrate the level of sensitivity and specificity by titrating total RNA extracted from cell culture infected with Human coronavirus 229E spiked into 100 ng human RNA extracted from GM12878 to give approximate figures.
Although not tested here, work performed by Josh Quick et al. on the Zika virus gives approximate dilution factors that may help reduction of inhibiting compounds that can be co-extracted from samples.
Note: this is a guideline and not currently tested for SARS-CoV-2.
qPCR ct Dilution factor 18–35 none 15–18 1:10 12–15 1:100 When processing multiple samples at once, we recommend making master mixes with an additional 10% of the volume. We also recommend using pre- and post-PCR hoods when handling master mixes and samples. It is important to clean and/or UV irradiate these hoods between sample batches. Furthermore, to track and monitor cross-contamination events, it is important to run a negative control reaction at the reverse transcription stage using nuclease-free water instead of sample, and carrying this control through the rest of the prep.
To minimise the chance of pipetting errors when preparing primer mixes, we recommend ordering the tiling primers from IDT in a lab-ready format at 100 µM.

Equipment and consumables
- Materials
-
- Input RNA in 10 mM Tris-HCl, pH 8.0
- Ligation Sequencing Kit (SQK-LSK109)
- Native Barcoding Expansion 96 (EXP-NBD196)
- Flow Cell Priming Kit (EXP-FLP002)
- SFB Expansion (EXP-SFB001)
- Consumables
-
- LunaScript™ RT SuperMix Kit (NEB, cat # E3010)
- Q5® Hot Start High-Fidelity 2X Master Mix (NEB, cat # M0494)
- SARS-CoV-2 primers (lab-ready at 100 µM, IDT)
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Agencourt AMPure XP beads (Beckman Coulter™, A63881)
- Freshly prepared 80% ethanol in nuclease-free water
- NEB Blunt/TA Ligase Master Mix (NEB, M0367)
- NEBNext® Ultra II End Repair / dA-tailing Module (NEB, E7546)
- NEBNext Quick Ligation Module (NEB, E6056)
- Hamilton 50 µl CO-RE tips with filter (Cat# 235948)
- Hamilton 300 µl CO-RE tips with filter (Cat# 235903)
- Hamilton 1000 µl CO-RE tips with filter (Cat# 235905)
- Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid (Cat# 56694-01)
- Roche Diagnotics MagNA Pure LC Medium Reagent Tubs 20 (Cat# 03004058001)
- Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate (ThermoFisher, Cat # AB0859)
- Hamilton PCR ComfortLid (Cat# 814300)
- Sarstedt Inc Screw Cap Micro tube 2 ml, PP 1000/case (e.g. FisherScientific, Cat# NC0418367)
- 1.5 ml Eppendorf DNA LoBind tubes
- Bio-Rad Hard-Shell® 96-Well PCR Plates (Cat# HSP9601)
- Qubit dsDNA HS Assay Kit (ThermoFisher, Q32851)
- Equipment
-
- Microplate centrifuge, e.g. Fisherbrand™ Mini Plate Spinner Centrifuge (Fisher Scientific, 11766427)
- Vortex mixer
- Thermal cycler
- Multichannel pipette and tips
- P1000 pipette and tips
- P200 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
- P2 pipette and tips
- Ice bucket with ice
- Timer
- Optional Equipment
-
- Qubit fluorometer (or equivalent for QC check)
- PCR hood with UV steriliser (optional but recommended to reduce cross-contamination)
- PCR-Cooler (Eppendorf)
-
Input RNA guidelines
Where sample RNA is added to the below reaction, it is likely advantageous to follow the dilution guidelines proposed by Josh Quick:
qPCR Ct Dilution factor 18–35 none 15–18 1:10 12–15 1:100 If the sample has a low copy number (ct 18–35) use up to 16 µl of sample. Use nuclease-free water to make up any remaining volume. Take note to be aware that co-extracted compounds may inhibit reverse transcription and PCR.
-
Input File Worklist
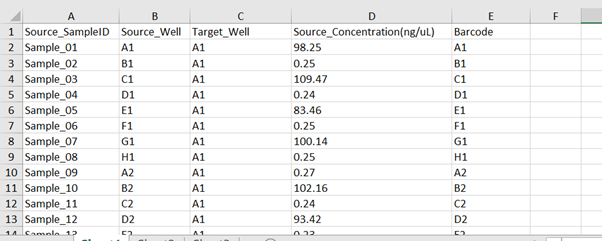
Two worklist input excel files are required prior to running the protocol on the Hamilton NGS Star: one for processes03 to 08 and another for processes10 to 11. These will contain information regarding the appropriate number of samples, well identifiers and source concentration. In the first worklist, the target well is the well for pooled samples at the end of Process07. A maximum of 24 samples should be combined to make each pool, so for 96 samples, there will be 4 pools in target wells A1 to D1. Samples should be split evenly, so that the pools contain equivalent volumes. This worklist must be updated after the automated library preparation sections with the relevant plate information. Note that the pools are combined at the end of process08 into well A2, so the Source_Well for the second worklist will be A2.
Example:
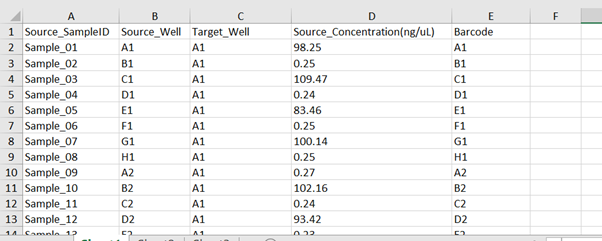
-
Hamilton NGS Star 96 and deck layout
This method has been tested and validated using the Hamilton NGS Star 96 (with 8 channels and MPH96), including an on-deck thermal cycler (ODTC), a Hamilton Heater Shaker (HHS) and the Inheco Cold Plate Air Cooled (CPAC) Modules. All modules are used at different stages of the protocol. This protocol may require some fine tuning for the specific NGS Star set-up and the temperature/humidity of the customer laboratory.
Please contact your Hamilton representative for further details.
Deck layout
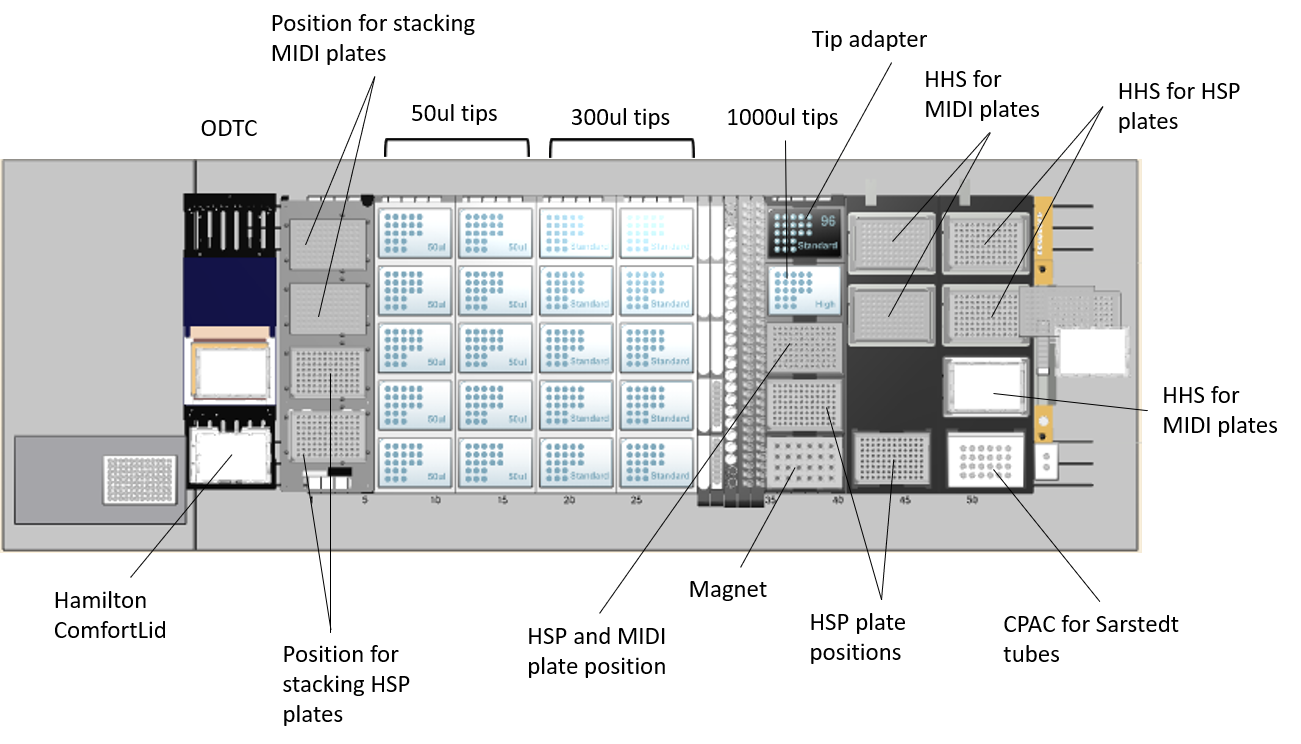
- MIDI plates: Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate (ThermoFisher, Cat # AB0859)
- HSP plates: Bio-Rad Hard-Shell® 96-Well PCR Plates (Cat# HSP9601)
- ODTC: On-Deck Thermal Cycler Module
- HHS: Hamilton Heater Shaker Module
- CPAC: Inheco Cold Plate Air Cooled Module
- 20 ml reagent troughs: X150 Reagent tub MagNA Pure LC medium 20 plastic (zigzag troughs, Roche #03004058001
- 60 ml self-standing large troughs (Hamilton, 56694-01)
-
Consumables and reagent quantities required:
Consumables X24 samples X48 samples X96 samples Hamilton 50 µl CO-RE tips with filter 293 561 1097 Hamilton 300 µl CO-RE tips with filter 108 206 402 Hamilton 1000 µl CO-RE tips with filter 91 109 145 Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid 5 5 5 Hamilton PCR ComfortLid 2 2 2 Bio-Rad Hard-Shell® 96-Well PCR Plate 10 10 10 Roche Diagnostics MagNA Pure LC Medium Reagent Tubs 20 5 5 5 Sarstedt Inc Screw Cap Micro Tube 2ml 4 6 8 Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate 4 4 4 1.5 ml Eppendorf DNA LoBind tubes 4 4 4 Reagents/kits X24 samples X48 samples X96 samples AMPure XP Beads 7.639 ml 9.256 ml 12.422 ml 80% ethanol 24.6 ml 35.3 ml 56.4 ml Nuclease-free water 16 ml 16.7 ml 19.9 ml NEBNext Ultra II End Repair/dA-Tailing Module (Cat# E7546) 1 small kit 2 small kits 2 small kits NEB Blunt/TA Ligase Master Mix (M0367) 2 small kits 3 small kits 1 large kit NEBNext Quick Ligation Module (Cat# E6056) 1 small kit 1 small kit 1 small kit Native Barcoding Expansion 96 (EXP-NBD196) 1 kit 1 kit 1 kit Ligation Sequencing Kit (SQK-LSK109) 1 kit 1 kit 1 kit SFB Expansion (EXP-SFB001) 1 kit
(3 tubes)1 kit
(3 tubes)1 kit
(4 tubes)LunaScript™ RT SuperMix Kit 1 small kit 2 small kits 1 large kit Q5® Hot Start High-Fidelity 2X Master Mix (NEB, M0494) 1 small kit 1 small kit 1 small kit Note: These quantities are for one run of the protocol for the selected number of samples.
-
Native Barcoding Expansion 96 (EXP-NBD196) contents
Kits in batches NBD196.10.0007 onwards have barcodes ordered in columns on the plate:

Kits in batches prior to NBD196.10.0007 have barcodes ordered in rows:

Name Acronym Cap colour No. of vials Fill volume per vial (μl) Native Barcode 01-96 NB01-96 - 1 plate 40 μl per well Adapter Mix II AMII Green 1 70 -
Ligation Sequencing Kit contents (SQK-LSK109)

Name Acronym Cap colour No. of vials Fill volume per vial (µl) DNA CS DCS Yellow 1 50 Adapter Mix AMX Green 1 40 Ligation Buffer LNB Clear 1 200 L Fragment Buffer LFB White cap, orange stripe on label 2 1,800 S Fragment Buffer SFB Grey 2 1,800 Sequencing Buffer SQB Red 2 300 Elution Buffer EB Black 1 200 Loading Beads LB Pink 1 360 -
Flow Cell Priming Kit contents (EXP-FLP002)
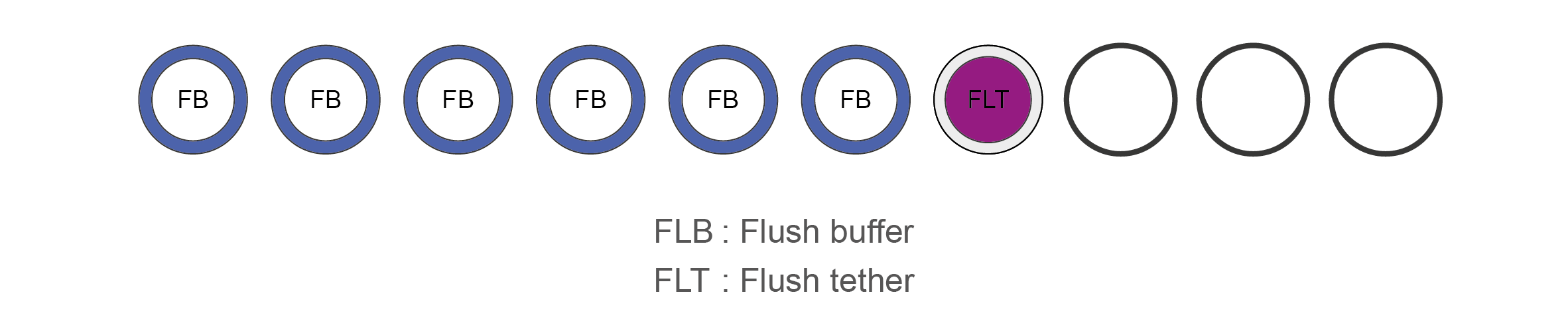
Name Acronym Cap colour No. of vials Fill volume per vial (μl) Flush Buffer FB Blue 6 1,170 Flush Tether FLT Purple 1 200 -
SFB Expansion contents (EXP-SFB001)

Name Acronym Cap colour No. of vials Fill volume per vial (μl) Short Fragment Buffer SFB Grey 4 1,800 -
Native barcode sequences
Component Forward sequence Reverse sequence NB01 CACAAAGACACCGACAACTTTCTT AAGAAAGTTGTCGGTGTCTTTGTG NB02 ACAGACGACTACAAACGGAATCGA TCGATTCCGTTTGTAGTCGTCTGT NB03 CCTGGTAACTGGGACACAAGACTC GAGTCTTGTGTCCCAGTTACCAGG NB04 TAGGGAAACACGATAGAATCCGAA TTCGGATTCTATCGTGTTTCCCTA NB05 AAGGTTACACAAACCCTGGACAAG CTTGTCCAGGGTTTGTGTAACCTT NB06 GACTACTTTCTGCCTTTGCGAGAA TTCTCGCAAAGGCAGAAAGTAGTC NB07 AAGGATTCATTCCCACGGTAACAC GTGTTACCGTGGGAATGAATCCTT NB08 ACGTAACTTGGTTTGTTCCCTGAA TTCAGGGAACAAACCAAGTTACGT NB09 AACCAAGACTCGCTGTGCCTAGTT AACTAGGCACAGCGAGTCTTGGTT NB10 GAGAGGACAAAGGTTTCAACGCTT AAGCGTTGAAACCTTTGTCCTCTC NB11 TCCATTCCCTCCGATAGATGAAAC GTTTCATCTATCGGAGGGAATGGA NB12 TCCGATTCTGCTTCTTTCTACCTG CAGGTAGAAAGAAGCAGAATCGGA NB13 AGAACGACTTCCATACTCGTGTGA TCACACGAGTATGGAAGTCGTTCT NB14 AACGAGTCTCTTGGGACCCATAGA TCTATGGGTCCCAAGAGACTCGTT NB15 AGGTCTACCTCGCTAACACCACTG CAGTGGTGTTAGCGAGGTAGACCT NB16 CGTCAACTGACAGTGGTTCGTACT AGTACGAACCACTGTCAGTTGACG NB17 ACCCTCCAGGAAAGTACCTCTGAT ATCAGAGGTACTTTCCTGGAGGGT NB18 CCAAACCCAACAACCTAGATAGGC GCCTATCTAGGTTGTTGGGTTTGG NB19 GTTCCTCGTGCAGTGTCAAGAGAT ATCTCTTGACACTGCACGAGGAAC NB20 TTGCGTCCTGTTACGAGAACTCAT ATGAGTTCTCGTAACAGGACGCAA NB21 GAGCCTCTCATTGTCCGTTCTCTA TAGAGAACGGACAATGAGAGGCTC NB22 ACCACTGCCATGTATCAAAGTACG CGTACTTTGATACATGGCAGTGGT NB23 CTTACTACCCAGTGAACCTCCTCG CGAGGAGGTTCACTGGGTAGTAAG NB24 GCATAGTTCTGCATGATGGGTTAG CTAACCCATCATGCAGAACTATGC NB25 GTAAGTTGGGTATGCAACGCAATG CATTGCGTTGCATACCCAACTTAC NB26 CATACAGCGACTACGCATTCTCAT ATGAGAATGCGTAGTCGCTGTATG NB27 CGACGGTTAGATTCACCTCTTACA TGTAAGAGGTGAATCTAACCGTCG NB28 TGAAACCTAAGAAGGCACCGTATC GATACGGTGCCTTCTTAGGTTTCA NB29 CTAGACACCTTGGGTTGACAGACC GGTCTGTCAACCCAAGGTGTCTAG NB30 TCAGTGAGGATCTACTTCGACCCA TGGGTCGAAGTAGATCCTCACTGA NB31 TGCGTACAGCAATCAGTTACATTG CAATGTAACTGATTGCTGTACGCA NB32 CCAGTAGAAGTCCGACAACGTCAT ATGACGTTGTCGGACTTCTACTGG NB33 CAGACTTGGTACGGTTGGGTAACT AGTTACCCAACCGTACCAAGTCTG NB34 GGACGAAGAACTCAAGTCAAAGGC GCCTTTGACTTGAGTTCTTCGTCC NB35 CTACTTACGAAGCTGAGGGACTGC GCAGTCCCTCAGCTTCGTAAGTAG NB36 ATGTCCCAGTTAGAGGAGGAAACA TGTTTCCTCCTCTAACTGGGACAT NB37 GCTTGCGATTGATGCTTAGTATCA TGATACTAAGCATCAATCGCAAGC NB38 ACCACAGGAGGACGATACAGAGAA TTCTCTGTATCGTCCTCCTGTGGT NB39 CCACAGTGTCAACTAGAGCCTCTC GAGAGGCTCTAGTTGACACTGTGG NB40 TAGTTTGGATGACCAAGGATAGCC GGCTATCCTTGGTCATCCAAACTA NB41 GGAGTTCGTCCAGAGAAGTACACG CGTGTACTTCTCTGGACGAACTCC NB42 CTACGTGTAAGGCATACCTGCCAG CTGGCAGGTATGCCTTACACGTAG NB43 CTTTCGTTGTTGACTCGACGGTAG CTACCGTCGAGTCAACAACGAAAG NB44 AGTAGAAAGGGTTCCTTCCCACTC GAGTGGGAAGGAACCCTTTCTACT NB45 GATCCAACAGAGATGCCTTCAGTG CACTGAAGGCATCTCTGTTGGATC NB46 GCTGTGTTCCACTTCATTCTCCTG CAGGAGAATGAAGTGGAACACAGC NB47 GTGCAACTTTCCCACAGGTAGTTC GAACTACCTGTGGGAAAGTTGCAC NB48 CATCTGGAACGTGGTACACCTGTA TACAGGTGTACCACGTTCCAGATG NB49 ACTGGTGCAGCTTTGAACATCTAG CTAGATGTTCAAAGCTGCACCAGT NB50 ATGGACTTTGGTAACTTCCTGCGT ACGCAGGAAGTTACCAAAGTCCAT NB51 GTTGAATGAGCCTACTGGGTCCTC GAGGACCCAGTAGGCTCATTCAAC NB52 TGAGAGACAAGATTGTTCGTGGAC GTCCACGAACAATCTTGTCTCTCA NB53 AGATTCAGACCGTCTCATGCAAAG CTTTGCATGAGACGGTCTGAATCT NB54 CAAGAGCTTTGACTAAGGAGCATG CATGCTCCTTAGTCAAAGCTCTTG NB55 TGGAAGATGAGACCCTGATCTACG CGTAGATCAGGGTCTCATCTTCCA NB56 TCACTACTCAACAGGTGGCATGAA TTCATGCCACCTGTTGAGTAGTGA NB57 GCTAGGTCAATCTCCTTCGGAAGT ACTTCCGAAGGAGATTGACCTAGC NB58 CAGGTTACTCCTCCGTGAGTCTGA TCAGACTCACGGAGGAGTAACCTG NB59 TCAATCAAGAAGGGAAAGCAAGGT ACCTTGCTTTCCCTTCTTGATTGA NB60 CATGTTCAACCAAGGCTTCTATGG CCATAGAAGCCTTGGTTGAACATG NB61 AGAGGGTACTATGTGCCTCAGCAC GTGCTGAGGCACATAGTACCCTCT NB62 CACCCACACTTACTTCAGGACGTA TACGTCCTGAAGTAAGTGTGGGTG NB63 TTCTGAAGTTCCTGGGTCTTGAAC GTTCAAGACCCAGGAACTTCAGAA NB64 GACAGACACCGTTCATCGACTTTC GAAAGTCGATGAACGGTGTCTGTC NB65 TTCTCAGTCTTCCTCCAGACAAGG CCTTGTCTGGAGGAAGACTGAGAA NB66 CCGATCCTTGTGGCTTCTAACTTC GAAGTTAGAAGCCACAAGGATCGG NB67 GTTTGTCATACTCGTGTGCTCACC GGTGAGCACACGAGTATGACAAAC NB68 GAATCTAAGCAAACACGAAGGTGG CCACCTTCGTGTTTGCTTAGATTC NB69 TACAGTCCGAGCCTCATGTGATCT AGATCACATGAGGCTCGGACTGTA NB70 ACCGAGATCCTACGAATGGAGTGT ACACTCCATTCGTAGGATCTCGGT NB71 CCTGGGAGCATCAGGTAGTAACAG CTGTTACTACCTGATGCTCCCAGG NB72 TAGCTGACTGTCTTCCATACCGAC GTCGGTATGGAAGACAGTCAGCTA NB73 AAGAAACAGGATGACAGAACCCTC GAGGGTTCTGTCATCCTGTTTCTT NB74 TACAAGCATCCCAACACTTCCACT AGTGGAAGTGTTGGGATGCTTGTA NB75 GACCATTGTGATGAACCCTGTTGT ACAACAGGGTTCATCACAATGGTC NB76 ATGCTTGTTACATCAACCCTGGAC GTCCAGGGTTGATGTAACAAGCAT NB77 CGACCTGTTTCTCAGGGATACAAC GTTGTATCCCTGAGAAACAGGTCG NB78 AACAACCGAACCTTTGAATCAGAA TTCTGATTCAAAGGTTCGGTTGTT NB79 TCTCGGAGATAGTTCTCACTGCTG CAGCAGTGAGAACTATCTCCGAGA NB80 CGGATGAACATAGGATAGCGATTC GAATCGCTATCCTATGTTCATCCG NB81 CCTCATCTTGTGAAGTTGTTTCGG CCGAAACAACTTCACAAGATGAGG NB82 ACGGTATGTCGAGTTCCAGGACTA TAGTCCTGGAACTCGACATACCGT NB83 TGGCTTGATCTAGGTAAGGTCGAA TTCGACCTTACCTAGATCAAGCCA NB84 GTAGTGGACCTAGAACCTGTGCCA TGGCACAGGTTCTAGGTCCACTAC NB85 AACGGAGGAGTTAGTTGGATGATC GATCATCCAACTAACTCCTCCGTT NB86 AGGTGATCCCAACAAGCGTAAGTA TACTTACGCTTGTTGGGATCACCT NB87 TACATGCTCCTGTTGTTAGGGAGG CCTCCCTAACAACAGGAGCATGTA NB88 TCTTCTACTACCGATCCGAAGCAG CTGCTTCGGATCGGTAGTAGAAGA NB89 ACAGCATCAATGTTTGGCTAGTTG CAACTAGCCAAACATTGATGCTGT NB90 GATGTAGAGGGTACGGTTTGAGGC GCCTCAAACCGTACCCTCTACATC NB91 GGCTCCATAGGAACTCACGCTACT AGTAGCGTGAGTTCCTATGGAGCC NB92 TTGTGAGTGGAAAGATACAGGACC GGTCCTGTATCTTTCCACTCACAA NB93 AGTTTCCATCACTTCAGACTTGGG CCCAAGTCTGAAGTGATGGAAACT NB94 GATTGTCCTCAAACTGCCACCTAC GTAGGTGGCAGTTTGAGGACAATC NB95 CCTGTCTGGAAGAAGAATGGACTT AAGTCCATTCTTCTTCCAGACAGG NB96 CTGAACGGTCATAGAGTCCACCAT ATGGTGGACTCTATGACCGTTCAG







Computer requirements and software
Computer requirements and software
-
MinION Mk1B IT requirements
Sequencing on a MinION Mk1B requires a high-spec computer or laptop to keep up with the rate of data acquisition. For more information, refer to the MinION Mk1B IT requirements document.
-
MinION Mk1C IT requirements
The MinION Mk1C contains fully-integrated compute and screen, removing the need for any accessories to generate and analyse nanopore data. For more information refer to the MinION Mk1C IT requirements document.
-
MinION Mk1D IT requirements
Sequencing on a MinION Mk1D requires a high-spec computer or laptop to keep up with the rate of data acquisition. For more information, refer to the MinION Mk1D IT requirements document.
-
Software for nanopore sequencing
MinKNOW
The MinKNOW software controls the nanopore sequencing device, collects sequencing data and basecalls in real time. You will be using MinKNOW for every sequencing experiment to sequence, basecall and demultiplex if your samples were barcoded.
For instructions on how to run the MinKNOW software, please refer to the MinKNOW protocol.
EPI2ME (optional)
The EPI2ME cloud-based platform performs further analysis of basecalled data, for example alignment to the Lambda genome, barcoding, or taxonomic classification. You will use the EPI2ME platform only if you would like further analysis of your data post-basecalling.
For instructions on how to create an EPI2ME account and install the EPI2ME Desktop Agent, please refer to this link.
-
Check your flow cell
We highly recommend that you check the number of pores in your flow cell prior to starting a sequencing experiment. This should be done within 12 weeks of purchasing for MinION/GridION/PromethION or within four weeks of purchasing Flongle Flow Cells. Oxford Nanopore Technologies will replace any flow cell with fewer than the number of pores in the table below, when the result is reported within two days of performing the flow cell check, and when the storage recommendations have been followed. To do the flow cell check, please follow the instructions in the Flow Cell Check document.
Flow cell Minimum number of active pores covered by warranty Flongle Flow Cell 50 MinION/GridION Flow Cell 800 PromethION Flow Cell 5000
Library preparation
Reverse transcription
Reverse transcription
- Materials
-
- Input RNA in 10 mM Tris-HCl, pH 8.0
- Consumables
-
- LunaScript™ RT SuperMix Kit (NEB, cat # E3010)
- Hard-Shell® 96-Well PCR Plates, low profile, thin-walled, skirted, white/clear (Bio-Rad, Cat # HSP9601)
- Equipment
-
- P200 pipette and tips
- P2 pipette and tips
- Thermal cycler
- Microfuge
- Ice bucket with ice
- Optional Equipment
-
- PCR-Cooler (Eppendorf)
- PCR hood with UV steriliser (optional but recommended to reduce cross-contamination)
-
Consumables and reagent quantities:
Consumables X24, X48 and X96 samples Hard-Shell® 96-Well PCR Plates 1 Reagents X24 samples X48 samples X96 samples LunaScript™ RT SuperMix (5x) 96 µl 192 µl 384 µl -
In a clean pre-PCR hood, mix together the following components in each well of a 96-well plate on ice or in a PCR cool rack, such as the Eppendorf PCR-Cooler:
Reagent Volume per well RNA sample 16 µl LunaScript RT SuperMix (5x) 4 µl Total 20 µl Note: We recommend using up to 16 µl of RNA sample. Use nuclease-free water to make up the final volume to 16 µl if required.
-
Mix gently by pipetting, and spin down. Return the plate to ice.
-
Preheat the thermal cycler to 25°C.
-
Incubate the samples in the thermal cycler using the following program:
Step Temperature Time Cycles Primer annealing 25°C 2 min 1 cDNA synthesis 55°C 10 min 1 Heat inactivation 95°C 1 min 1 Hold 4°C ∞
PCR tiling
PCR tiling
- Consumables
-
- SARS-CoV-2 primers (lab-ready at 100 µM, IDT)
- Q5® Hot Start High-Fidelity 2X Master Mix (NEB, cat # M0494)
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- 1.5 ml Eppendorf DNA LoBind tubes
- Bio-Rad Hard-Shell® 96-Well PCR Plates (Cat# HSP9601)
- Equipment
-
- Microfuge
- Eppendorf 5424 centrifuge (or equivalent)
- Qubit fluorometer plate reader (or equivalent for QC check)
- Thermal cycler or heat block with 96 wells
- Multichannel pipette and tips
- P200 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
- P2 pipette and tips
- Optional Equipment
-
- PCR hood with UV steriliser (optional but recommended to reduce cross-contamination)
-
Consumable and reagent quantities:
Consumables X24, X48 and X96 samples 1.5 ml Eppendorf tubes 4 Bio-Rad Hard-Shell® 96-Well PCR Plates 3 Reagents X24 samples X48 samples X96 samples Q5® Hot Start High-Fidelity 2X Master Mix 300 µl 600 µl 1200 µl Primer pool at 10 µM (A or B) 88.8 µl 177.6 µl 355.2 µl Nuclease-free water 91.2 µl 182.4 µl 364.8 µl -
Primer design
To generate tiled PCR amplicons from the SARS-CoV-2 viral cDNA, primers were designed by Josh Quick using Primal Scheme. These primers are designed to generate 400 bp amplicons that overlap by approximately 20 bp. These primer sequences can be found here. Where we show example data outputs in this protocol, the same parameters were used to design primers to the human coronavirus 229E to provide guideline statistics.
-
If primers are supplied individually, add 5 µl of each primer from pool A per sample to a 1.5 ml Eppendorf DNA LoBind tube to give a 100 µM stock primer pool.
-
If primers are supplied individually, add 5 µl of each primer from pool B per sample to a 1.5 ml Eppendorf DNA LoBind tube to give a 100 µM stock primer pool.
-
Dilute each 100 µM stock 1 in 10 with nuclease-free water to form a working stock of each pool at 10 µM.
Note: To achieve the desired final concentration of each primer in the pool at 0.015 µM in the PCR reaction, 3.7 µl of the 10 µM working stock is needed for each PCR reaction. Two separate PCR reactions will be performed per sample, one for pool A primers and one for pool B. This results in tiled amplicons that have approximately 20 bp overlap.
-
In a clean pre-PCR hood, set up two individual reactions for primer pool A and primer pool B in clean 5 ml centrifuge tubes:
Reagent X24 samples X48 samples X96 samples Q5® Hot Start High-Fidelity 2X Master Mix 300 µl 600 µl 1200 µl Primer pool at 10 µM (A or B) 88.8 µl 177.6 µl 355.2 µl Nuclease-free water 91.2 µl 182.4 µl 364.8 µl Total 480 µl 960 µl 1920 µl -
In a clean 96-well plate, aliquot 20 µl of pool A reaction to each well per sample. Repeat in a new 96-well plate with pool B reaction. Add 5 µl of the reverse-transcribed samples per well in both plates.
-
Mix well by pipetting and spin down in a centrifuge.
-
Incubate using the following program, with the heated lid set to 105°C:
Step Temperature Time Cycles Initial denaturation 98°C 30 sec 1 Denaturation
Annealing and extension98°C
65°C15 sec
5 min
25–35Hold 4°C ∞ Note: Cycle number should be varied for low or high viral load samples. Guidelines provided by Josh Quick suggest that 25 cycles should be used for Ct 18–21 up to a maximum of 35 cycles for Ct 35, however this has not been tested here.
-
Combine the 25 µl reaction from pool A and the 25 µl reaction from pool B per sample, into a clean hard-shell fully skirted PCR plate to load on the NGS Star; one well per sample.
Note: Ensure the sample from pool A corresponds to the sample from pool B.
PCR tiling clean-up
PCR tiling clean-up
- Consumables
-
- Agencourt AMPure XP beads (Beckman Coulter™, A63881)
- Freshly prepared 80% ethanol in nuclease-free water
- Hamilton 50 µl CO-RE tips with filter (Cat# 235948)
- Hamilton 300 µl CO-RE tips with filter (Cat# 235903)
- Hamilton 1000 µl CO-RE tips with filter (Cat# 235905)
- Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid (Cat# 56694-01)
- Bio-Rad Hard-Shell® 96-Well PCR Plates (Cat# HSP9601)
- Equipment
-
- Vortex mixer
- Qubit fluorometer plate reader (or equivalent for QC check)
- Centrifuge capable of taking 96-well plates
- P1000 pipette and tips
- P200 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- Eppendorf 5424 centrifuge (or equivalent)
-
Consumables and equipment quantities:
Consumables X24 samples X48 samples X96 samples Hamilton 50 µl CO-RE tips with filter 72 144 288 Hamilton 300 µl CO-RE tips with filter 104 200 392 Hamilton 1000 µl CO-RE tips with filter 24 24 24 Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid 2 2 2 Bio-Rad Hard-Shell® 96-Well PCR Plate 2 2 2 Roche Diagnostics MagNA Pure LC Medium Reagent Tubs 20 1 1 1 Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate 1 1 1 -
Reagent quantities:
Reagents X24 samples X48 samples X96 samples AMPure XP Beads 3.3 ml 4.6 ml 7.2 ml 80% ethanol 17.5 ml 28.1 ml 49.2 ml Nuclease-free water 7.4 ml 7.7 ml 8.5 ml -
Switch on the Hamilton NGS STAR 96 robot and open 'Hamilton Run Control' on the computer by clicking the icon:
-
Select 'File' and 'Open' to choose the method to run: PCRtilingLSK109_v0.8.3.4MPH.med.
After a couple minutes, the software will connect to the instrument and the deck layout should appear.
Note: Ensure the Trace View and MLSTAR deck layout are selected at the top of the page with the instrument and the HHS, CPAC and ODTC are connected.
-

-
From Run Control, click the green play button to begin setting up the deck.

-
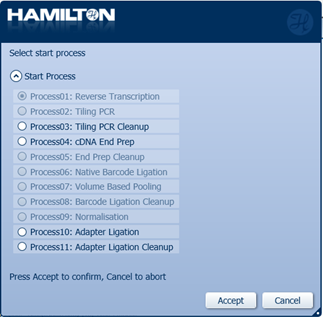
Select 'Process03: Tiling PCR Cleanup' as the start process.
-
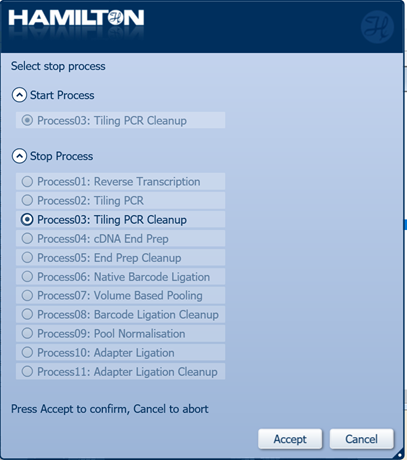
Select 'Process03: Tiling PCR Cleanup' as the Stop Process.
-
Click 'Browse' to upload the Input File Worklist for the specific samples with the relevant information in the run and click 'OK'.
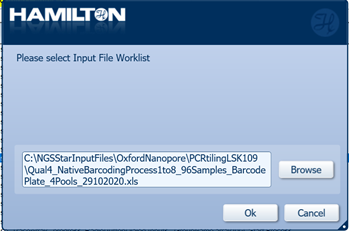
Relevant information required includes sample identification, well location and target well location.
Example sample sheet:
-
Insert plates in their corresponding positions displayed on screen. Click 'Ok' to continue.
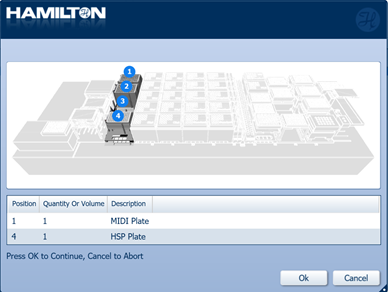
-
Load a full deck of 50 µl tips into the positions on screen. Click 'Ok' to continue.
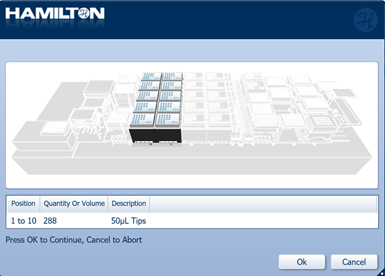
-
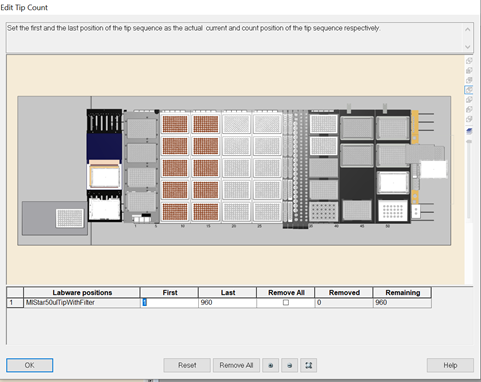
Update the first and last 50 µl tips available to use on the 'Edit Tip Count' window and click 'Ok' to continue.
Note: Click 'Remove All' twice if all the positions are not brown and update the tips available. There must be a tip rack (empty, partial or full) in every position. All tips in the tip racks also need to be input into the GUI to prevent a hardware crash.
-
Load a full deck of 300 µl tips in the positions on screen. Click 'Ok' to continue.
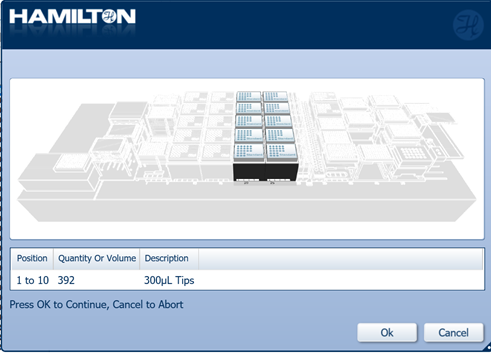
-
Update the first and last 300 µl tips available to use on the 'Edit Tip Count' window and click 'Ok' to continue.
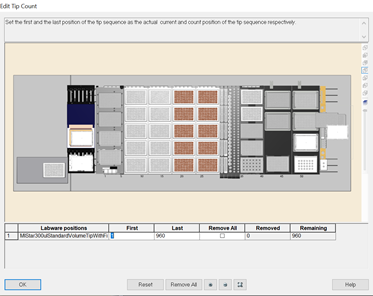
-
Freshly prepare 80% ethanol in nuclease-free water.
Reagents X24 samples X48 samples X96 samples 80% ethanol 17.5 ml 28.1 ml 49.2 ml -
Insert the trough of 80% ethanol in the position on screen and click 'Ok' to continue.
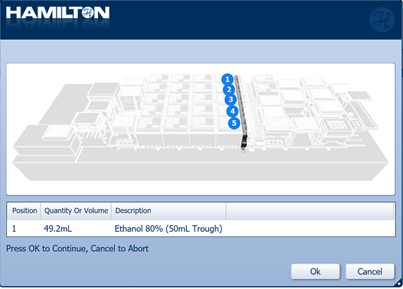
-
Prepare the nuclease-free water and resuspend the AMPure XP beads by vortexing.
Reagents X24 samples x48 samples x96 samples Nuclease-free water 7.4 ml 7.7 ml 8.5 ml AMPure XP beads 3.3 ml 4.6 ml 7.2 ml -
Insert the troughs of AMPure XP beads and nuclease-free water in their positions on screen. Click 'Ok' to continue.
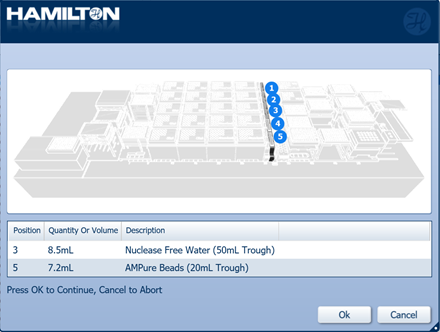
-
Load 1000 µl tips and insert the Tiling PCR Plate containing 50 µl DNA from the previous step into the positions on screen. Click 'Ok' to continue.
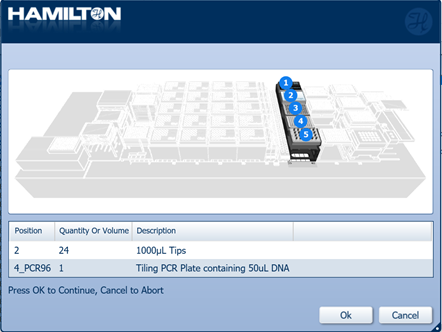
-
Update the first and last 1000 µl tips available to use in the 'Edit Tip Count' window and click 'Ok' to continue.
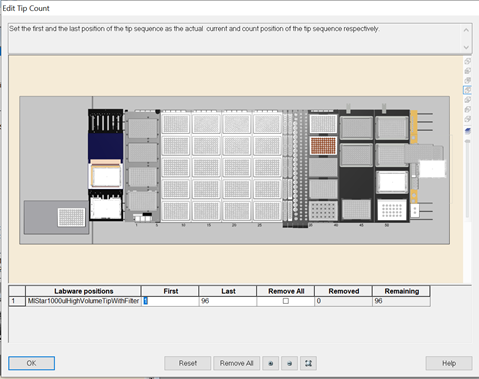
-
Click 'Ok' to start the run.

-
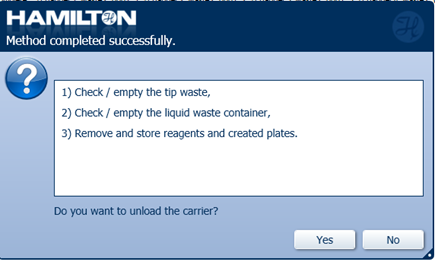
When the run is complete, unload the output plate. Click 'Ok' to continue.
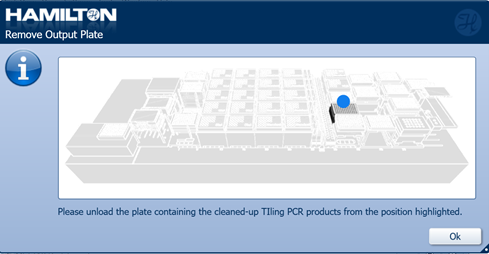
-
Do not unload the carrier by clicking 'No'.
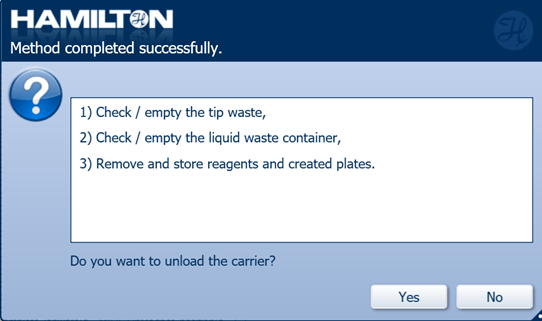
-
Click 'Ok' on the summary box to continue.
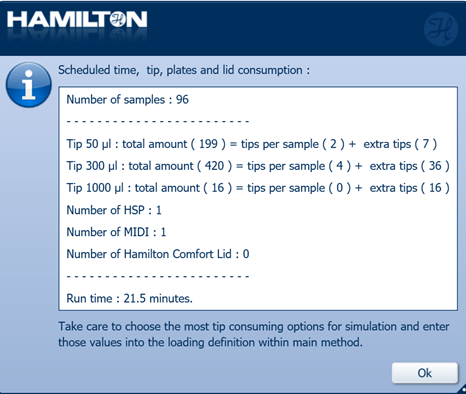
-
Quantify 1 µl of each eluted sample from the output plate using a Qubit fluorometer plate reader off deck.
-
Update the worklist with the measured concentration of purified PCR product.



















End-prep, native barcode ligation and clean-up
End-prep, native barcode ligation and clean-up
- Materials
-
- Native Barcoding Expansion 96 (EXP-NBD196)
- Short Fragment Buffer (SFB)
- Consumables
-
- NEBNext® Ultra II End Repair / dA-tailing Module (NEB, E7546)
- NEB Blunt/TA Ligase Master Mix (NEB, M0367)
- Agencourt AMPure XP beads (Beckman Coulter™, A63881)
- Freshly prepared 80% ethanol in nuclease-free water
- Hamilton 50 µl CO-RE tips with filter (Cat# 235948)
- Hamilton 300 µl CO-RE tips with filter (Cat# 235903)
- Hamilton 1000 µl CO-RE tips with filter (Cat# 235905)
- Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid (Cat# 56694-01)
- Hamilton PCR ComfortLid (Cat# 814300)
- Bio-Rad Hard-Shell® 96-Well PCR Plates (Cat# HSP9601)
- Roche Diagnotics MagNA Pure LC Medium Reagent Tubs 20 (Cat# 03004058001)
- Sarstedt Inc Screw Cap Micro tube 2 ml, PP 1000/case (e.g. FisherScientific, Cat# NC0418367)
- Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate (ThermoFisher, Cat # AB0859)
- Equipment
-
- Vortex mixer
- Centrifuge capable of taking 96-well plates
- Eppendorf 5424 centrifuge (or equivalent)
- Qubit fluorometer (or equivalent for QC check)
- P1000 pipette and tips
- P200 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
-
Consumables and equipment quantities:
Consumables X24 samples X48 samples X96 samples Hamilton 50 µl CO-RE tips with filter 215 411 803 Hamilton 300 µl CO-RE tips with filter 2 4 8 Hamilton 1000 µl CO-RE tips with filter 42 60 96 Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid 2 2 2 Hamilton PCR ComfortLid 1 1 1 Bio-Rad Hard-Shell® 96-Well PCR Plate 3 3 3 Roche Diagnostics MagNA Pure LC Medium Reagent Tubs 20 2 2 2 Sarstedt Inc Screw Cap Micro Tube 2ml 2 4 6 Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate 2 2 2 -
Reagent quantities:
Reagents X24 samples X48 samples X96 samples NEBNext Ultra II End-prep reaction buffer 87.5 µl 175 µl 315 µl NEBNext Ultra II End-prep enzyme mix 37.5 µl 75 µl 135 µl NEBNext Blunt/TA Ligase Master Mix (M0367) 350 µl 700 µl 1350 µl AMPure XP beads 2317 µl 2633.6 µl 3.2 ml 80% ethanol 7.1 ml 7.2 ml 7.2 ml Nuclease-free water 8.4 ml 8.8 ml 11 ml Short Fragment Buffer (SFB) 2550 µl 3.1 ml 4.2 ml -
Prepare the NEBNext Ultra II End repair / dA-tailing Module reagents in accordance with manufacturer’s instructions, and place on ice.
For optimal performance, NEB recommend the following:
- Thaw all reagents on ice.
- Flick and/or invert reagent tube to ensure they are well mixed.
- Always spin down tubes before opening for the first time each day.
- The Ultra II End prep buffer and FFPE DNA Repair buffer may have a little precipitate. Allow the mixture to come to room temperature and pipette the buffer up and down several times to break up the precipitate, followed by vortexing the tube for several seconds to ensure the reagent is thoroughly mixed.
- The FFPE DNA repair buffer may have a yellow tinge and is fine to use if yellow.
-
Thaw the native barcodes at room temperature, enough for one barcode per sample. Individually mix the barcodes by pipetting and load a minimum of 5 µl per well into a 96-well HSP plate. Store on ice.
-
Thaw the tube of Short Fragment Buffer (SFB) at room temperature, mix by vortexing, spin down and place on ice.
-
From Run Control, click the green play button to begin setting up the deck.
-
Select 'Process04: cDNA End Prep' to start.
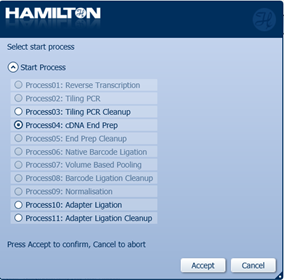
-
Select 'Process08: Barcode Ligation Cleanup' as the Stop Process.
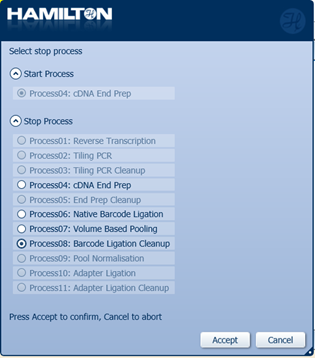
-
Click 'Browse' to upload the Input File Worklist with the updated sample concentrations and click 'OK'.
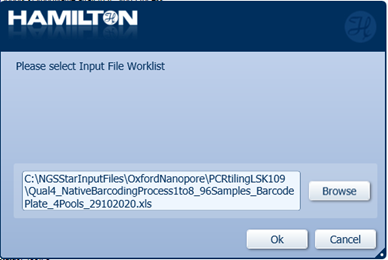
Note: If fewer than 96 samples are to be processed, ensure the positions of the barcodes in the barcode plate match those in the worklist.
-
Select 'Input samples require normalisation'.
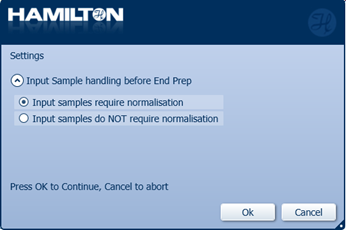
-
Fill in the normalisation settings as suggested below:
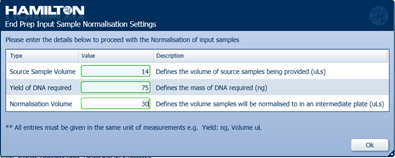
Note: If samples fall outside the recommended concentrations, a warning will appear. Click 'Ok' to continue.
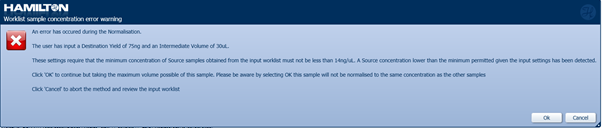
-
Prepare the End Prep Mastermix and Native Barcode Ligation Mastermix with the following reagents according to the Hamilton user interface. Select 'Yes' or 'No' to continue.
Note: It is user preference whether to save and print the instructions.
End-prep Mastermix:
Reagent X24 samples X48 samples X96 samples Ultra II End Prep Buffer 87.5 µl 175 µl 315 µl Ultra II End Prep Enzyme Mix 37.5 µl 75 µl 135 µl
Native Barcode Mastermix:Reagent X24 samples X48 samples X96 samples NEB Blunt/TA Ligase Master Mix 350 µl 700 µl 1350 µl 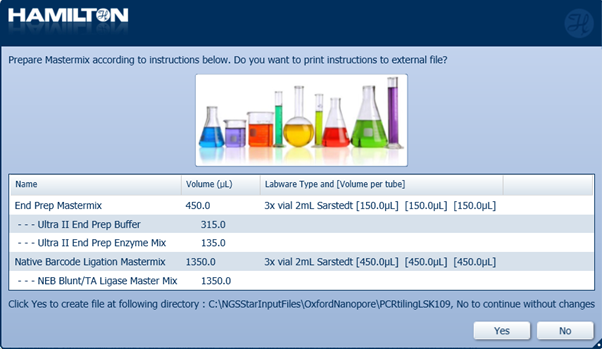
-
Insert the ComfortLid Rest Position as displayed on screen. Click 'Ok' to continue.
-
Insert plates to their corresponding positions on screen. Click 'Ok' to continue.
-
Load a full deck of 50 µl tips into the positions on screen. Click 'Ok' to continue.
-
Select the first and last tip positions to use in the 'Edit Tip Count' window. Click 'Ok' to continue.
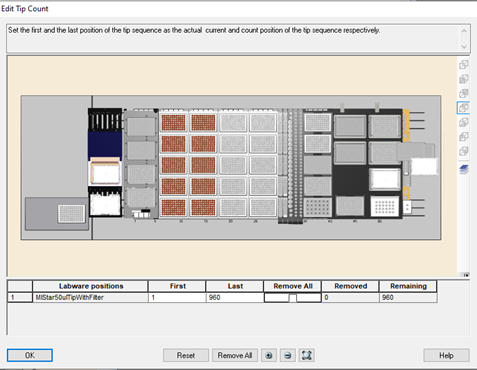
-
Load a full deck of 300 µl tips in the positions on screen. Click 'Ok' to continue.
-
Select the first and last tip positions to use in the 'Edit Tip Count' window. Click 'Ok' to continue.
-
Freshly prepare 80% ethanol in nuclease-free water.
Reagents X24 samples X48 samples X96 samples 80% ethanol 7.1 ml 7.2 ml 7.2 ml -
Insert the trough of freshly prepared 80% ethanol in the position on screen. Click 'Ok' to continue.
-
Resuspend the AMPure XP beads by vortexing.
-
Insert the nuclease-free water, Short Fragment Buffer (SFB) and AMPure XP beads in the positions on screen. Select 'Ok' to continue.
Reagent X24 samples X48 samples X96 samples Beads 2317 µl 2633.6 µl 3.2 ml Nuclease-free water 8.4 ml 8.8 ml 11 ml Short Fragment Buffer (SFB) 2550 µl 3.1 ml 4.2 ml 
-
Spin down the Post PCR Clean Up Samples and the Native Barcode plate (referenced as 'Input Barcode HSP plate').
-
Insert 1000 µl tips, Post PCR Clean Up Samples plate and the Input Barcode HSP plate to their correct positions on screen. Select 'Ok' to continue.
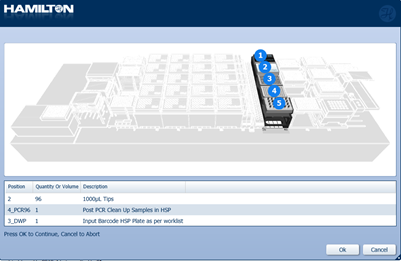
-
Select the first and last tip positions to use in the 'Edit Tip Count' window. Click 'Ok' to continue.
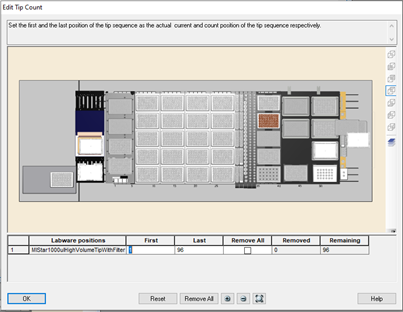
-
Mix and load the tubes of prepared mastermixes into their positions on screen. Select 'Ok' to start the run.
The status window in the bottom right of the screen will illustrate what the robot is doing.
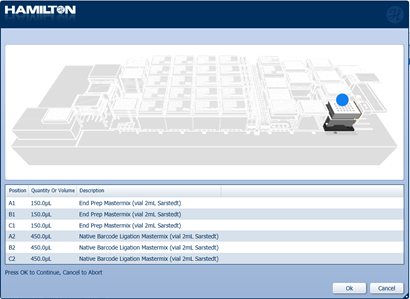
-

-
When the run is complete, unload the deck following the on screen instructions:
Output plate:

Barcode plate (if not previously removed):

Input sample plate:

Normalised sample plate:
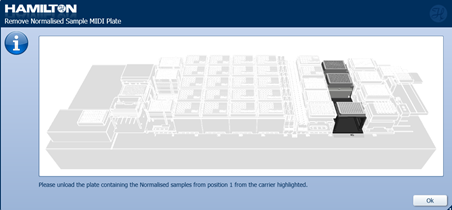
-
Do not unload the carrier by clicking 'No'.
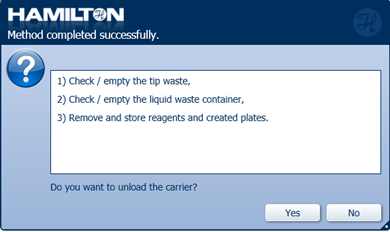
-
Click 'Ok' on the summary box to continue.
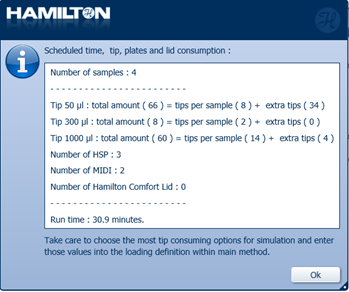
-
Quantify 1 µl of the pooled sample in the output plate using a Qubit fluorometer off deck.
-
Update the worklist with the measured concentration of the pooled sample for Processes 9-11.


























Adapter ligation and clean-up
Adapter ligation and clean-up
- Materials
-
- Elution Buffer (EB)
- Short Fragment Buffer (SFB)
- Adapter Mix II (AMII)
- Consumables
-
- NEBNext Quick Ligation Module (NEB, E6056)
- Agencourt AMPure XP beads (Beckman Coulter™, A63881)
- Hamilton 50 µl CO-RE tips with filter (Cat# 235948)
- Hamilton 300 µl CO-RE tips with filter (Cat# 235903)
- Hamilton 1000 µl CO-RE tips with filter (Cat# 235905)
- Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid (Cat# 56694-01)
- Bio-Rad Hard-Shell® 96-Well PCR Plates (Cat# HSP9601)
- Roche Diagnotics MagNA Pure LC Medium Reagent Tubs 20 (Cat# 03004058001)
- Sarstedt Inc Screw Cap Micro tube 2 ml, PP 1000/case (e.g. FisherScientific, Cat# NC0418367)
- Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate (ThermoFisher, Cat # AB0859)
- Equipment
-
- Vortex mixer
- Eppendorf 5424 centrifuge (or equivalent)
- Centrifuge capable of taking 96-well plates
- Qubit fluorometer (or equivalent for QC check)
-
Consumables quantities:
Consumables X24, X48 and X96 samples Hamilton 50 µl CO-RE tips with filter 6 Hamilton 300 µl CO-RE tips with filter 2 Hamilton 1000 µl CO-RE tips with filter 25 Hamilton 60 ml Reagent Reservoir, Self-Standing with Lid 1 Bio-Rad Hard-Shell® 96-Well PCR Plate 1 Roche Diagnostics MagNA Pure LC Medium Reagent Tubs 20 2 Sarstedt Inc Screw Cap Micro Tube 2ml 2 Abgene™ 96 Well 0.8mL Polypropylene Deepwell Storage Plate 1 -
Reagents required:
Reagents X24, X48 and X96 samples Adapter Mix II (AMII) 18.75 µl Short Fragment Buffer (SFB) 2250 µl Elution Buffer (EB) 35 µl NEBNext Quick Ligation Buffer 37.5 µl NEBNext T4 DNA Ligase 18.75 µl AMPure XP Beads 2022 µl -
Thaw the Elution Buffer (EB), Short Fragment Buffer (SFB), and NEBNext Quick Ligation Reaction Buffer (5x) at room temperature and mix by vortexing. Then spin down and place on ice. Check the contents of each tube are clear of any precipitate.
-
Spin down the T4 Ligase and the Adapter Mix II (AMII), and place on ice.
-
From Run Control, click the green play button to begin setting up the deck.
-
Select 'Process10: Adapter Ligation' to start.
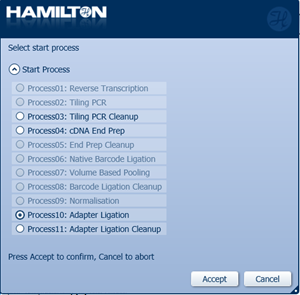
-
Select 'Process11: Adapter ligation cleanup' to stop the automated run and quantify the samples before sequencing.
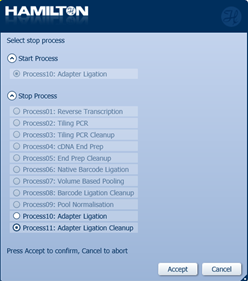
-
Click 'Browse' to upload the Input File Worklist with the updated sample concentrations and well identifications and click 'OK'.
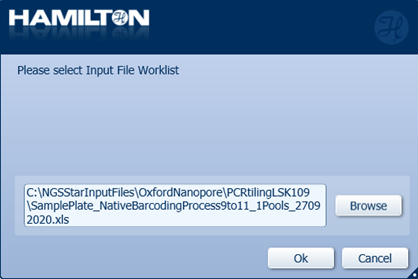
Update the worklist for the
Source_WellandTarget_Wellmatch the position of the pooled samples in the input plate.Note: It is possible to transfer pools from multiple runs into a single plate to run adapter ligation (process 10 and 11), up to a maximum of 8 source wells.

-
Prepare the Adapter Ligation Mastermix with the following reagents according to the Hamilton user interface. Click either 'Yes' or 'No' to continue.
Note: It is user preference whether to print and save the instructions.
Take care when pipetting the viscous AMII.
Reagents X24, X48 and X96 samples Adapter Mix II (AMII) 18.75 µl Quick T4 DNA Ligase 18.75 µl NEBNext Quick Ligation Reaction Buffer 37.5 µl 
-
Insert plates to their corresponding positions on screen. Select 'Ok' to continue.
-
If required, reload a full deck of 50 µl tips into the positions on screen. Select 'Ok' to continue.
Note: If there are enough tips left, there is no need to reload tips.
-
Select the first and last tip positions to use in the 'Edit Tip Count' window. Click 'Ok' to continue.
-
If required, reload a full deck of 300 µl tips into the positions on screen. Select 'Ok' to continue.
Note: If there are enough tips left from the previous run, there is no need to reload tips.
-
Select the first and last tip positions to use in the 'Edit Tip Count' window. Click 'Ok' to continue.
-
Resuspend the AMPure XP beads by vortexing.
-
Insert the Short Fragment Buffer (SFB) and AMPure XP beads in their positions on screen. Click 'Ok' to continue.
Reagents X24, X48 and X96 samples Short Fragment Buffer (SFB) 2250 µl Beads 2022 µl 
-
Insert the Elution Buffer (EB) in their position on screen. Click 'Ok' to continue.
Reagents X24, X48 and X96 samples Elution Buffer (EB) 35 µl 
-
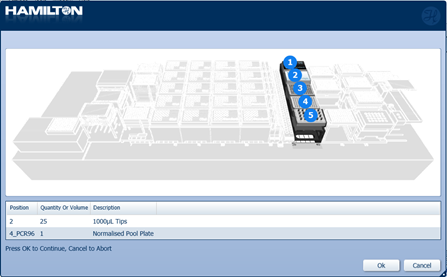
Load the 1000 µl tips and the Normalised Pool Plate to the correct positions on screen. Click 'Ok' to continue.
Note: The Normalised Pool Plate is the output plate from the previous step, containing the pooled barcoded samples.
-
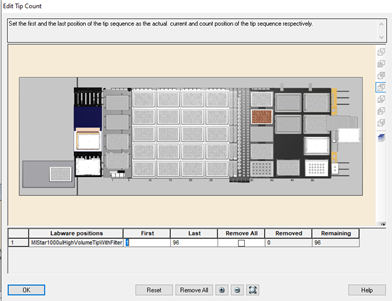
Highlight the 1000 µl tips available to use on the 'Edit Tip Count' window. Select 'Ok' to continue.
-
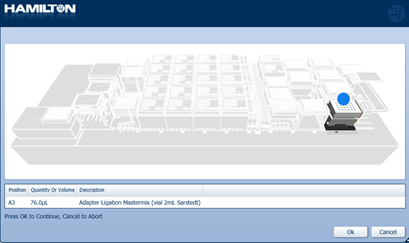
Mix and insert the prepared Adapter Ligation Mastermix into their positions on screen. Click 'Ok' to start the automated run.
-
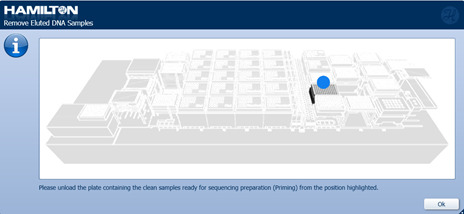
When the run is complete, unload the robot following the Hamilton user interface as below:
Eluted DNA samples:
Input Sample plate:

-
Do not unload the carrier by clicking 'No'.
-
Click 'Ok' on the summary box to continue.
-
Quantify 1 µl of each eluted sample in the Eluted DNA Samples plate using a Qubit fluorometer off deck.
-
Optional ActionIf quantities allow, the library may be diluted in Elution Buffer (EB) for splitting across multiple flow cells.
Additional buffer for doing this can be found in the Sequencing Auxiliary Vials expansion (EXP-AUX001), available to purchase separately. This expansion also contains additional vials of Sequencing Buffer (SQB) and Loading Beads (LB), required for loading the libraries onto flow cells.



















Priming and loading the SpotON Flow Cell
Priming and loading the SpotON Flow Cell
- Materials
-
- Flow Cell Priming Kit (EXP-FLP002)
- Sequencing Buffer (SQB)
- Loading Beads (LB)
- Consumables
-
- 1.5 ml Eppendorf DNA LoBind tubes
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Equipment
-
- MinION device
- SpotON Flow Cell
- MinION and GridION Flow Cell Light Shield
- P1000 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
-
Thaw the Sequencing Buffer (SQB), Loading Beads (LB), Flush Tether (FLT) and one tube of Flush Buffer (FB) at room temperature before mixing the reagents by vortexing, and spin down at room temperature.
-
To prepare the flow cell priming mix, add 30 µl of thawed and mixed Flush Tether (FLT) directly to the tube of thawed and mixed Flush Buffer (FB), and mix by vortexing at room temperature.
-
Open the MinION device lid and slide the flow cell under the clip.
Press down firmly on the flow cell to ensure correct thermal and electrical contact.


-
Optional ActionComplete a flow cell check to assess the number of pores available before loading the library.
This step can be omitted if the flow cell has been checked previously.
See the flow cell check instructions in the MinKNOW protocol for more information.
-
Slide the priming port cover clockwise to open the priming port.

-
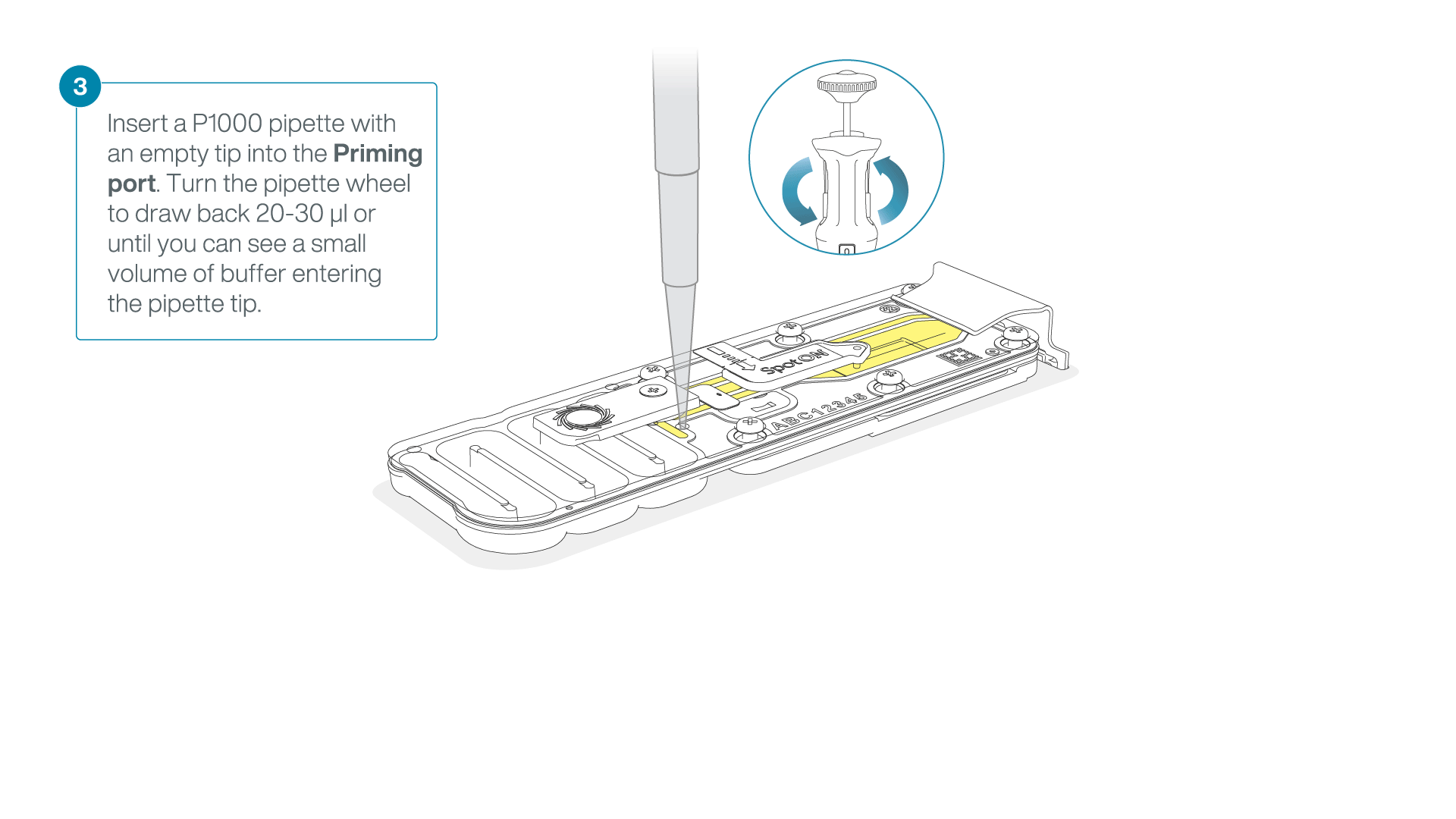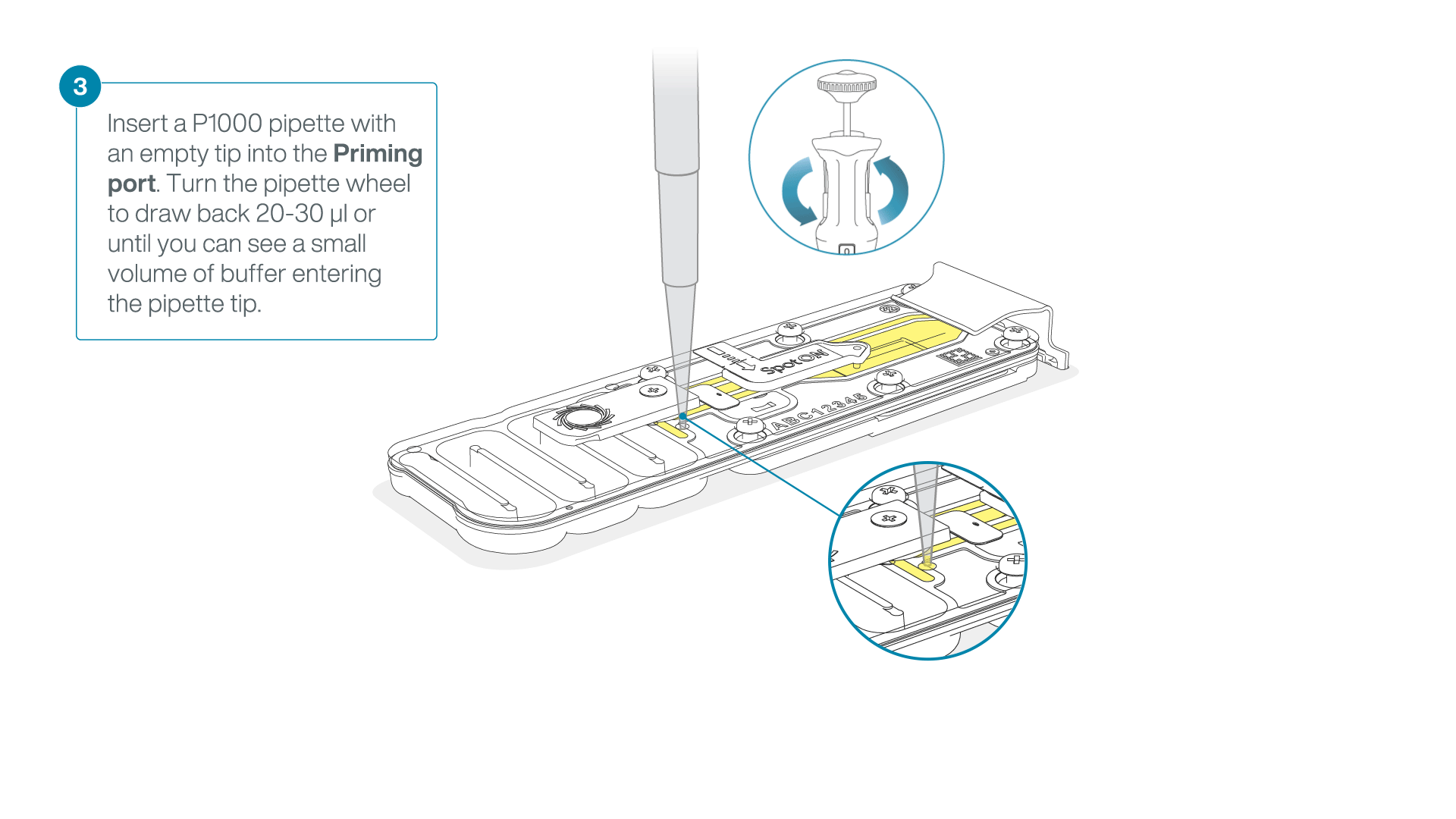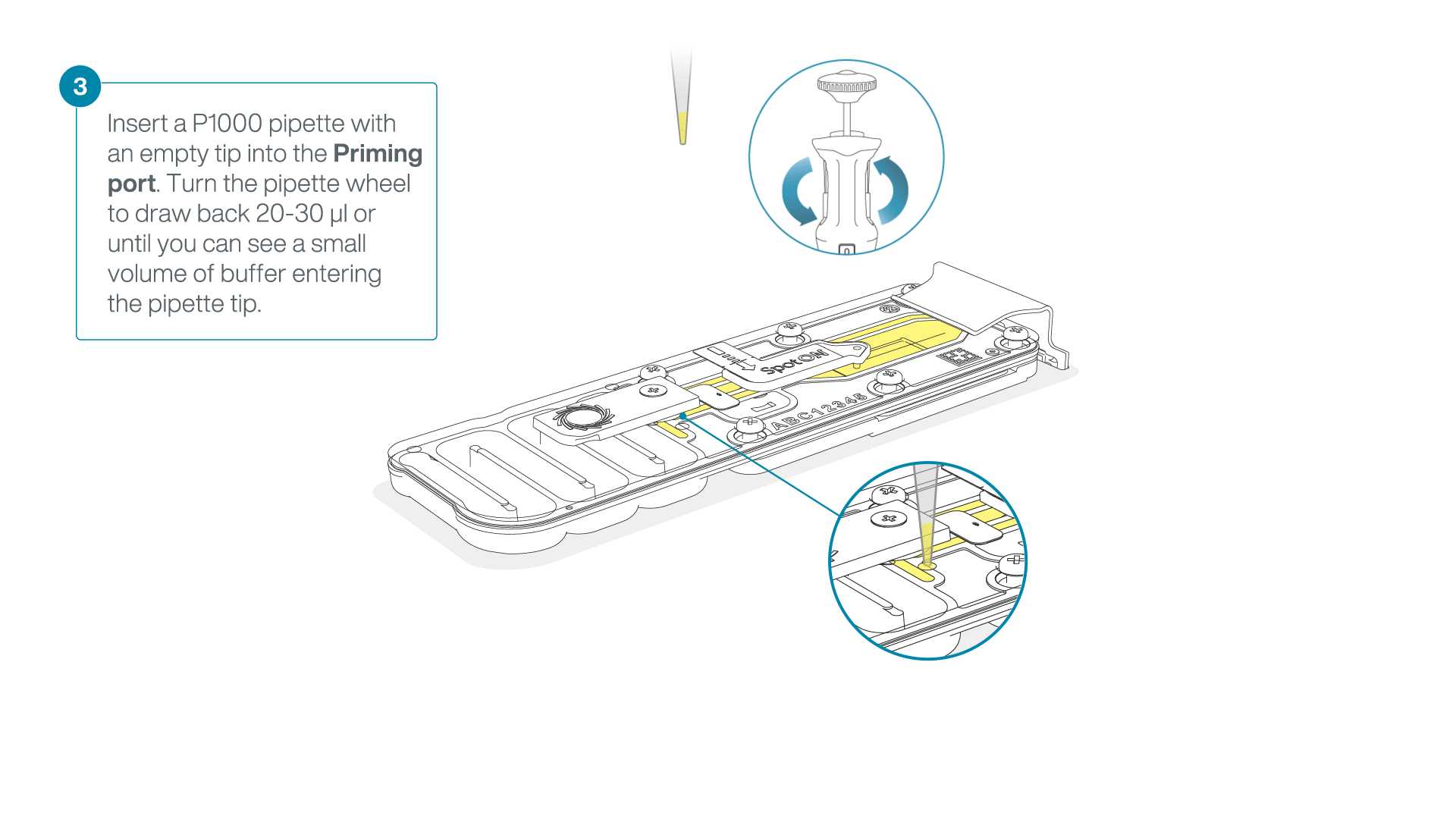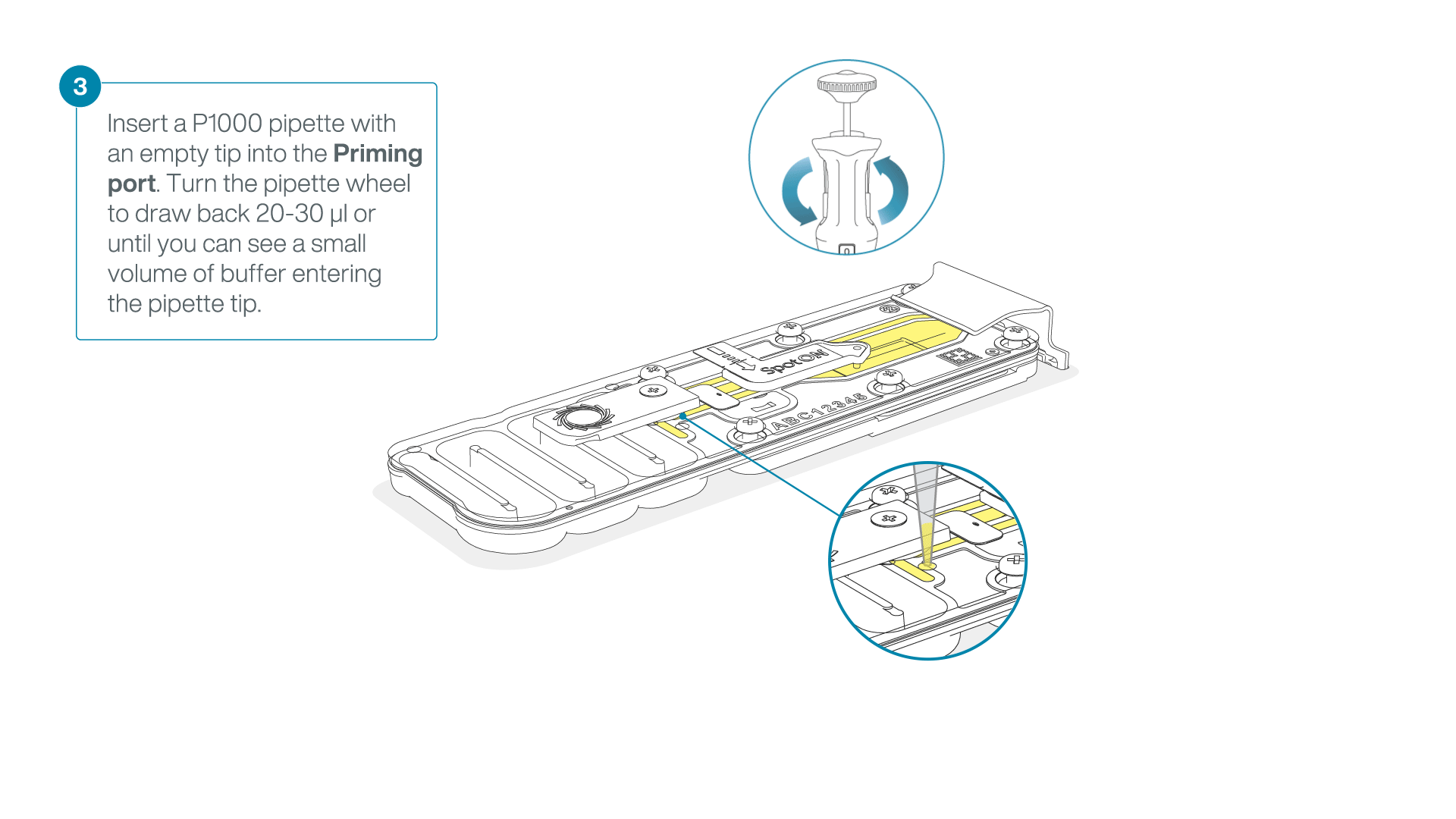
After opening the priming port, check for a small air bubble under the cover. Draw back a small volume to remove any bubbles:
- Set a P1000 pipette to 200 µl
- Insert the tip into the priming port
- Turn the wheel until the dial shows 220-230 µl, to draw back 20-30 µl, or until you can see a small volume of buffer entering the pipette tip
Note: Visually check that there is continuous buffer from the priming port across the sensor array.
-
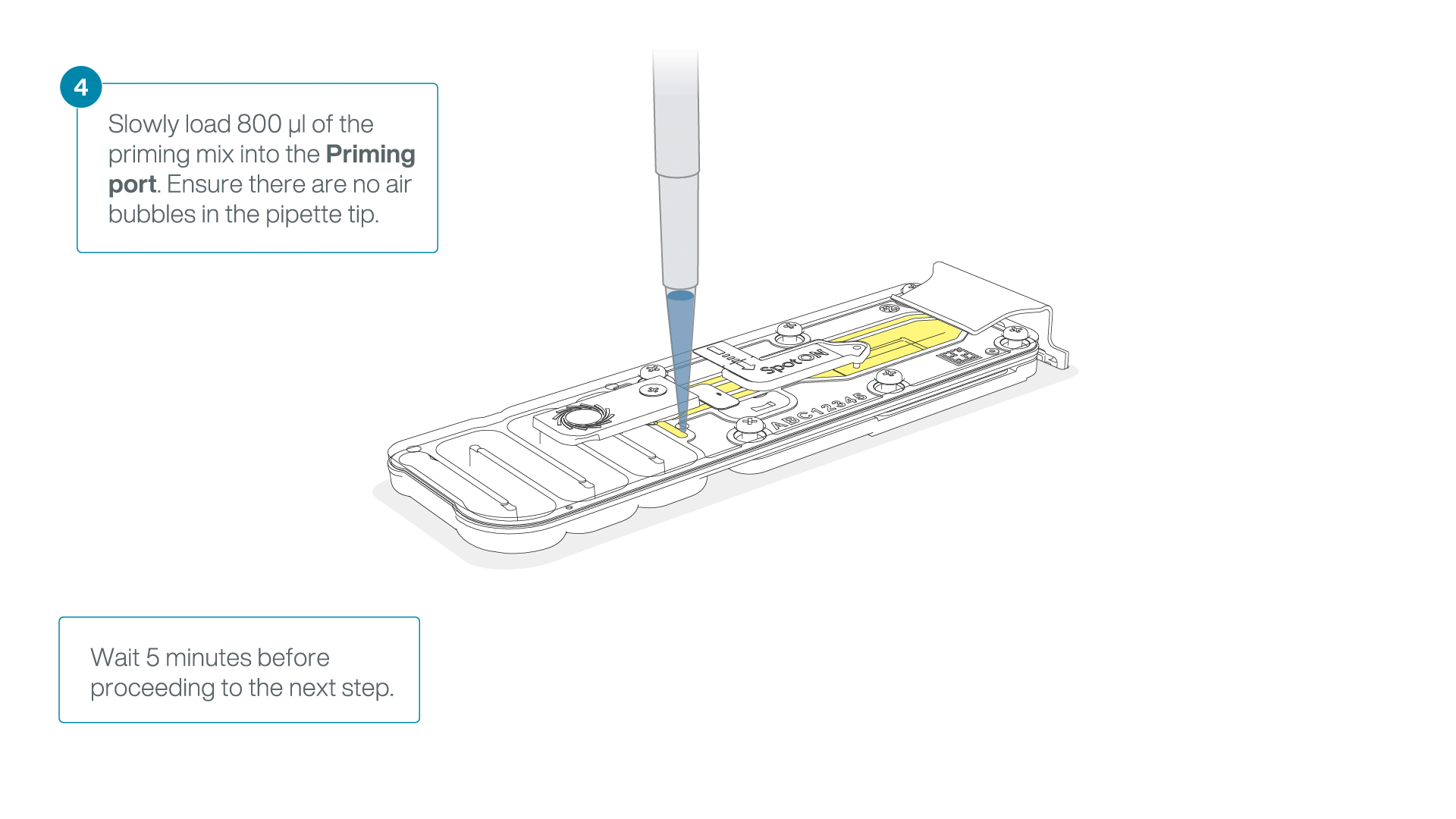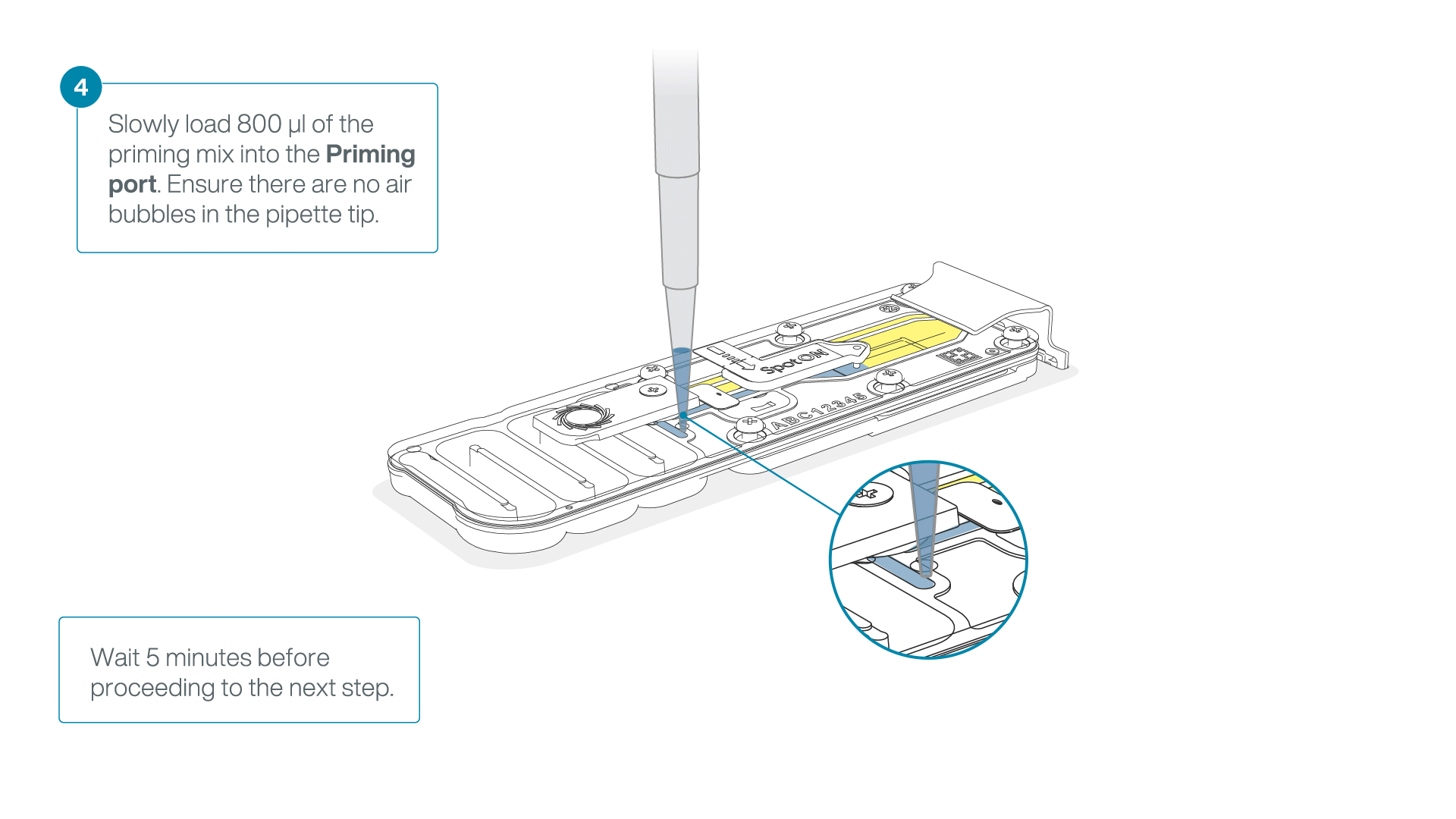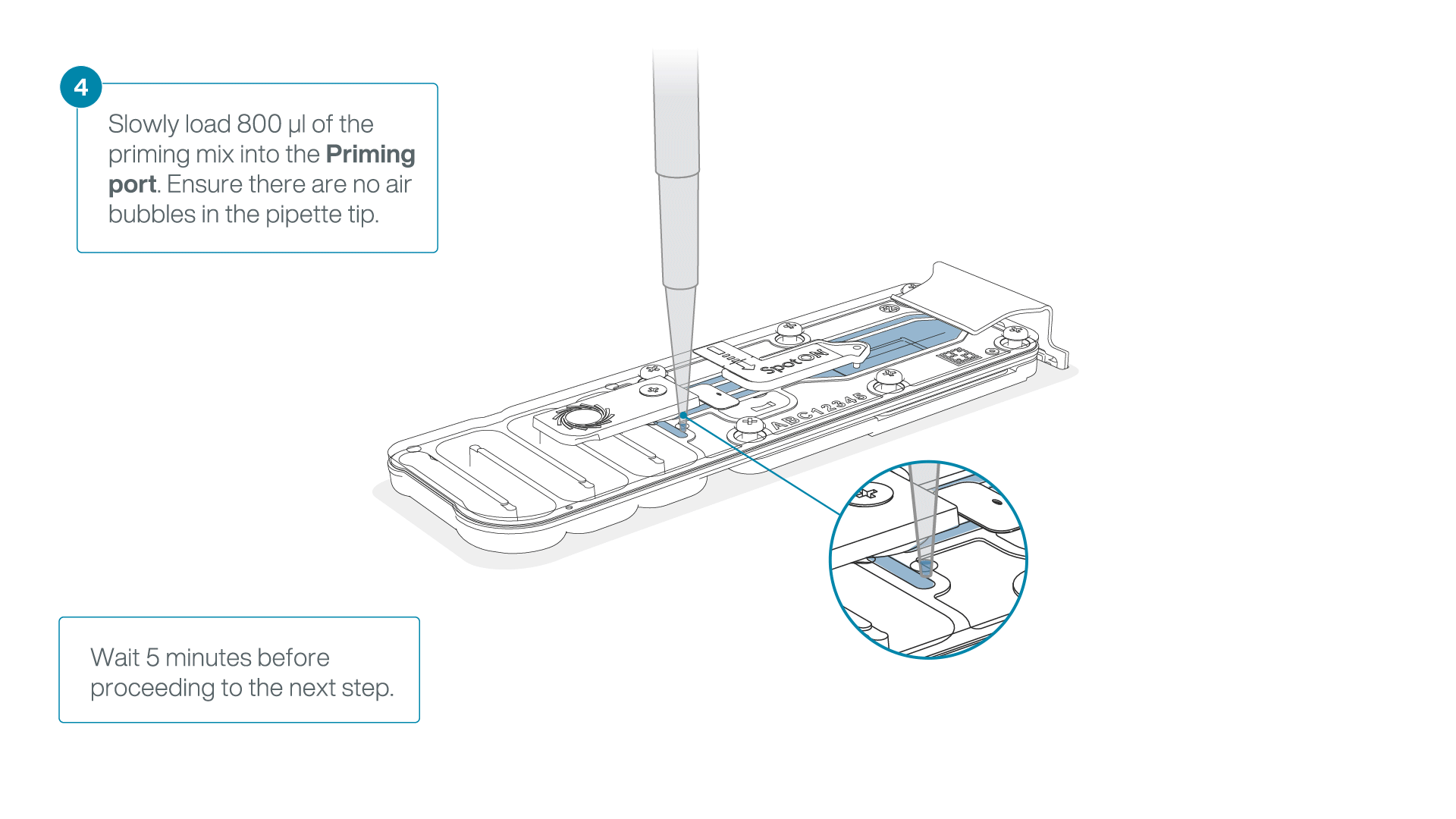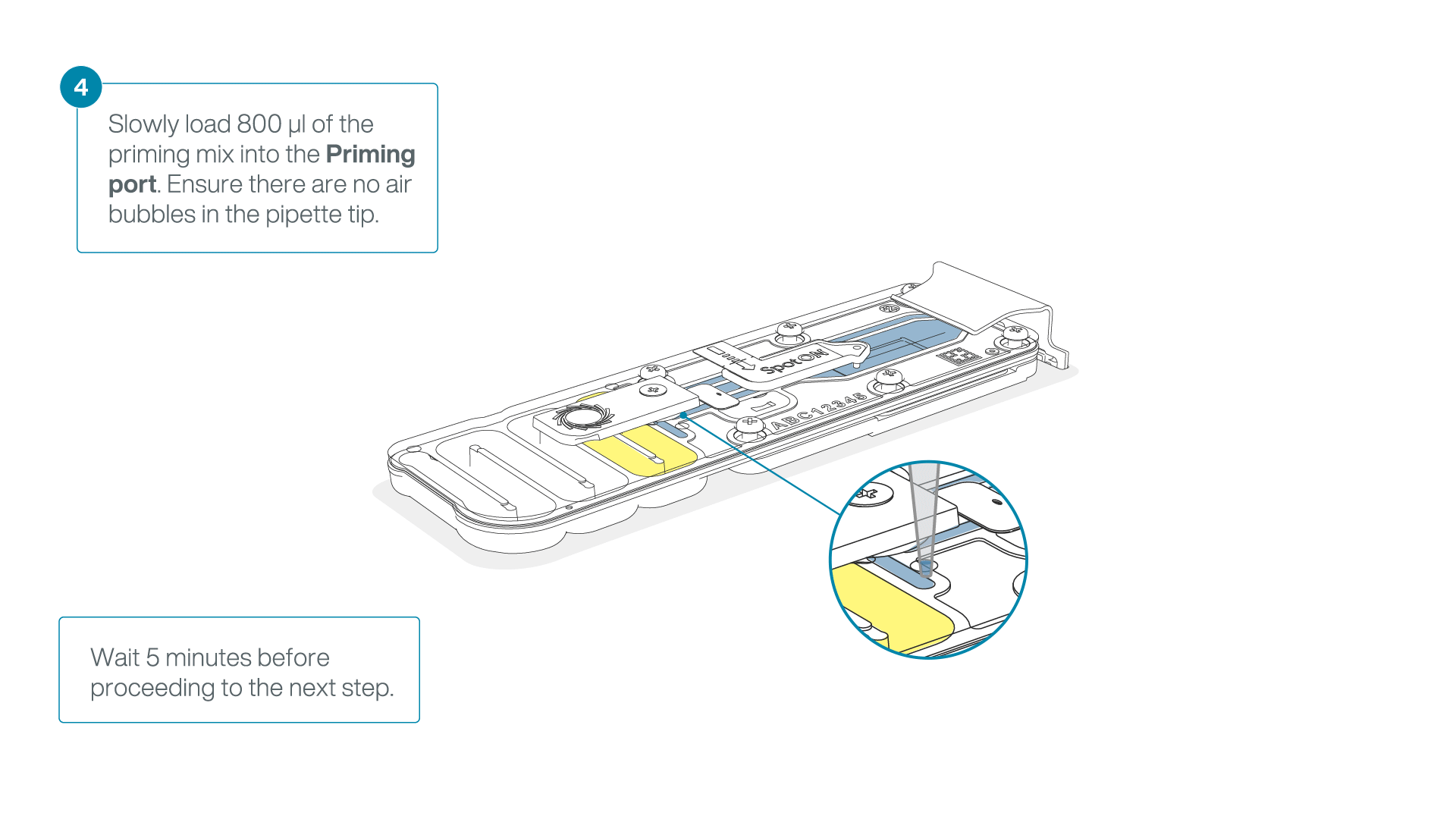
Load 800 µl of the priming mix into the flow cell via the priming port, avoiding the introduction of air bubbles. Wait for five minutes. During this time, prepare the library for loading by following the steps below.
-
Thoroughly mix the contents of the Loading Beads (LB) tubes by vortexing.
-
In a new tube, prepare the library for loading as follows:
Reagent Volume per flow cell Sequencing Buffer (SQB) 34 µl Loading Beads (LB), mixed immediately before use 25.5 µl Nuclease-free water 4.5 µl DNA library 11 µl Total 75 µl Note: Load the library onto the flow cell immediately after adding the Sequencing Buffer (SQB) and Loading Beads (LB) because the fuel in the buffer will start to be consumed by the adapter.
-
Complete the flow cell priming:
- Gently lift the SpotON sample port cover to make the SpotON sample port accessible.
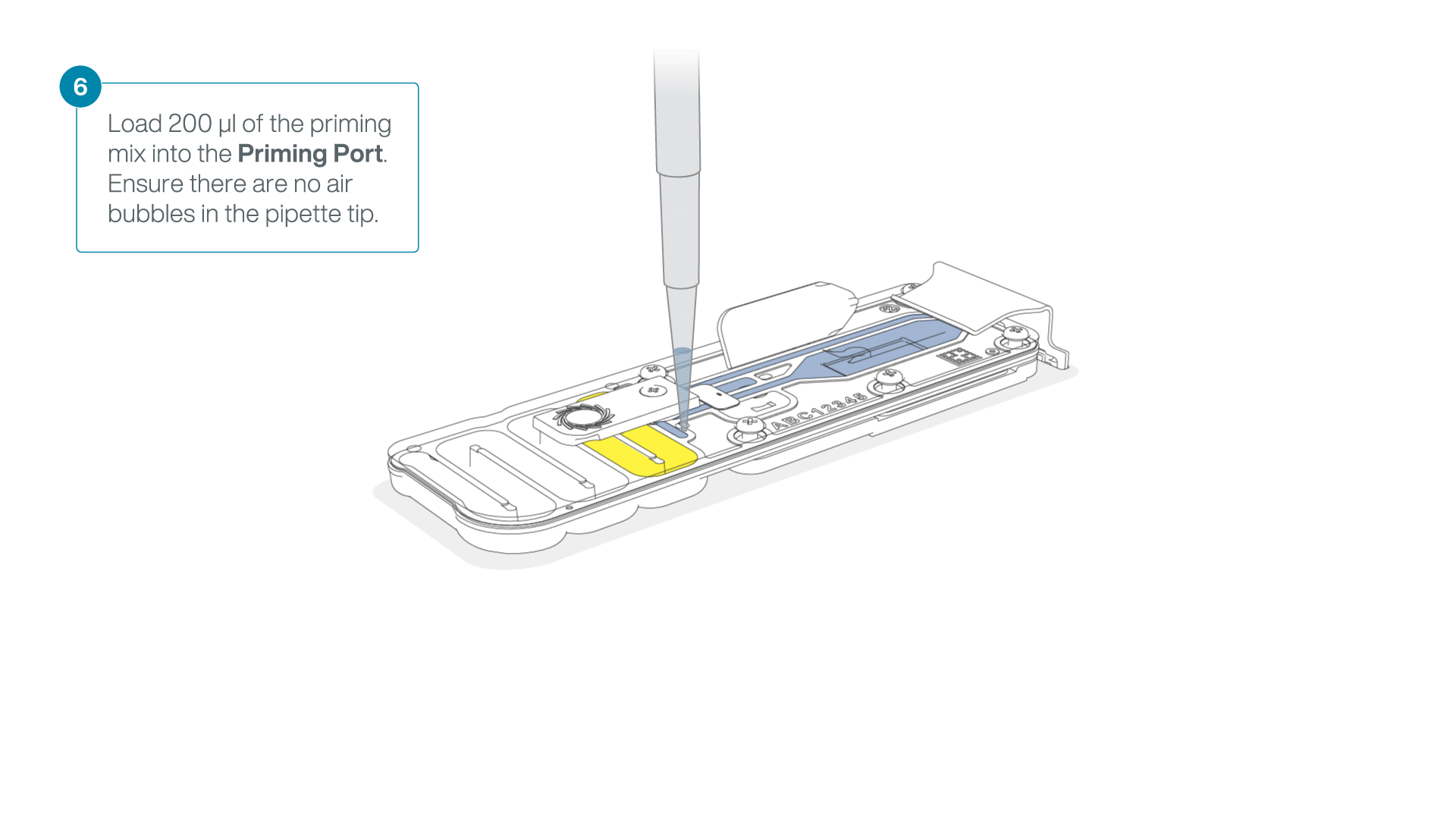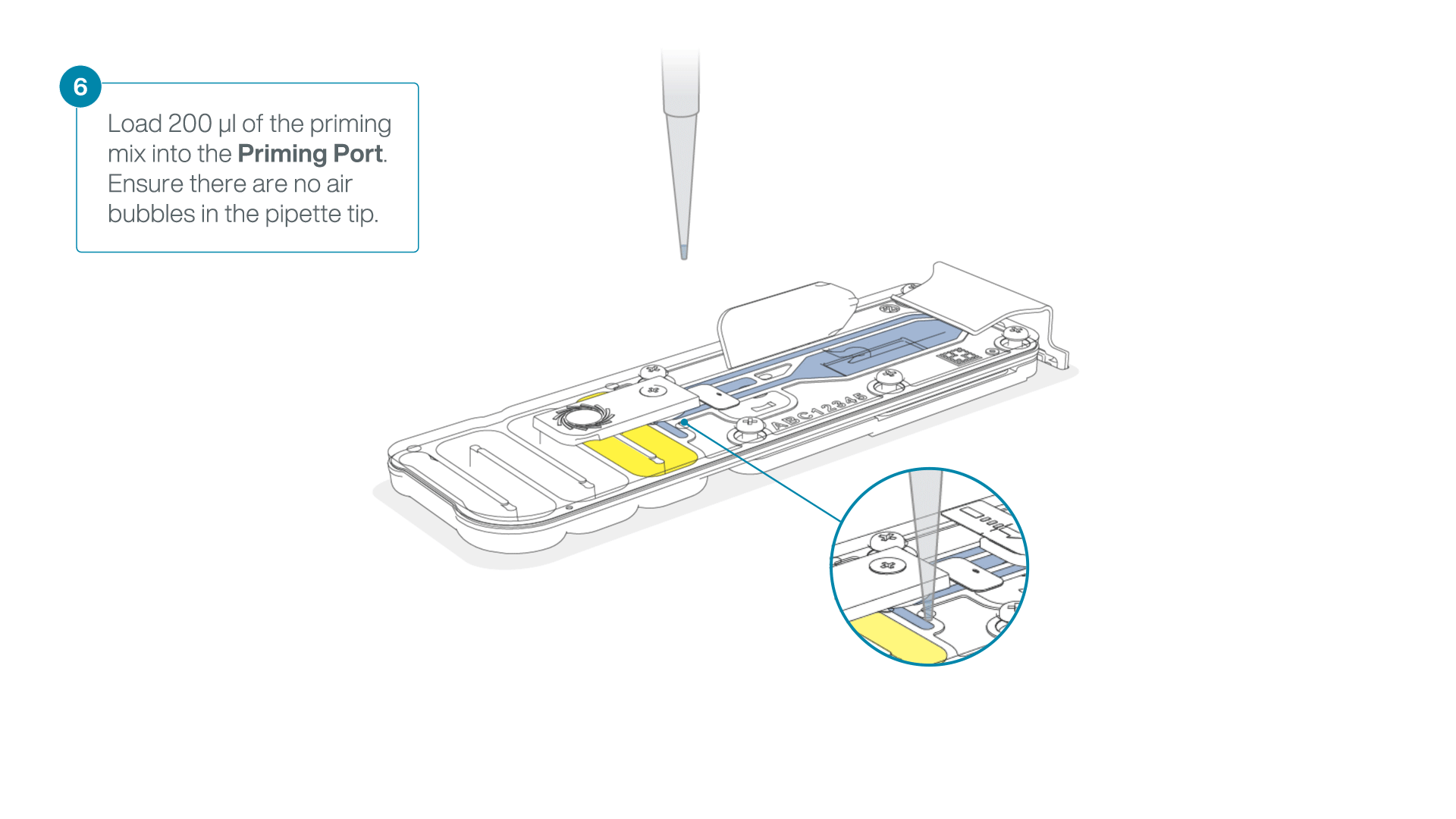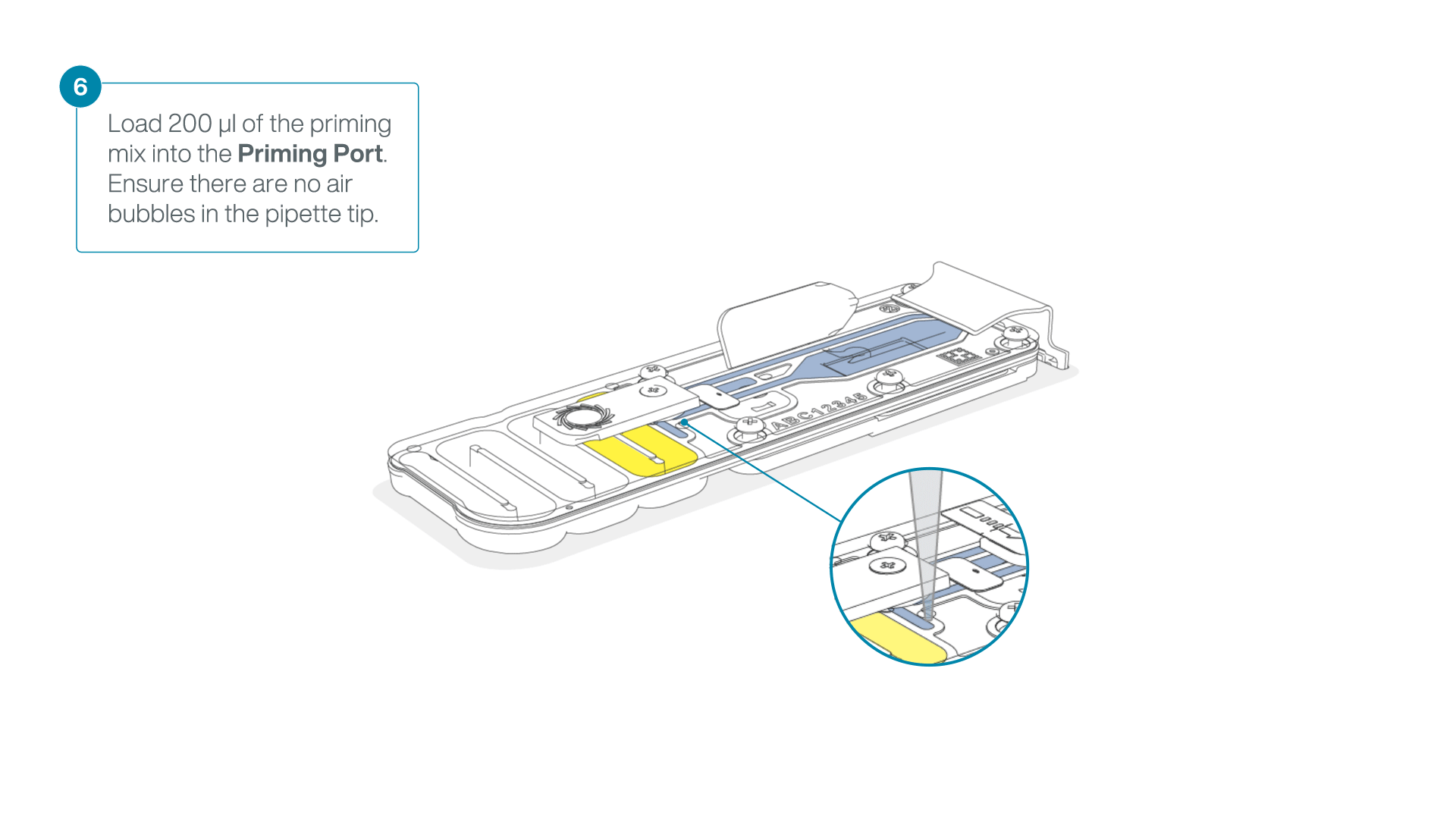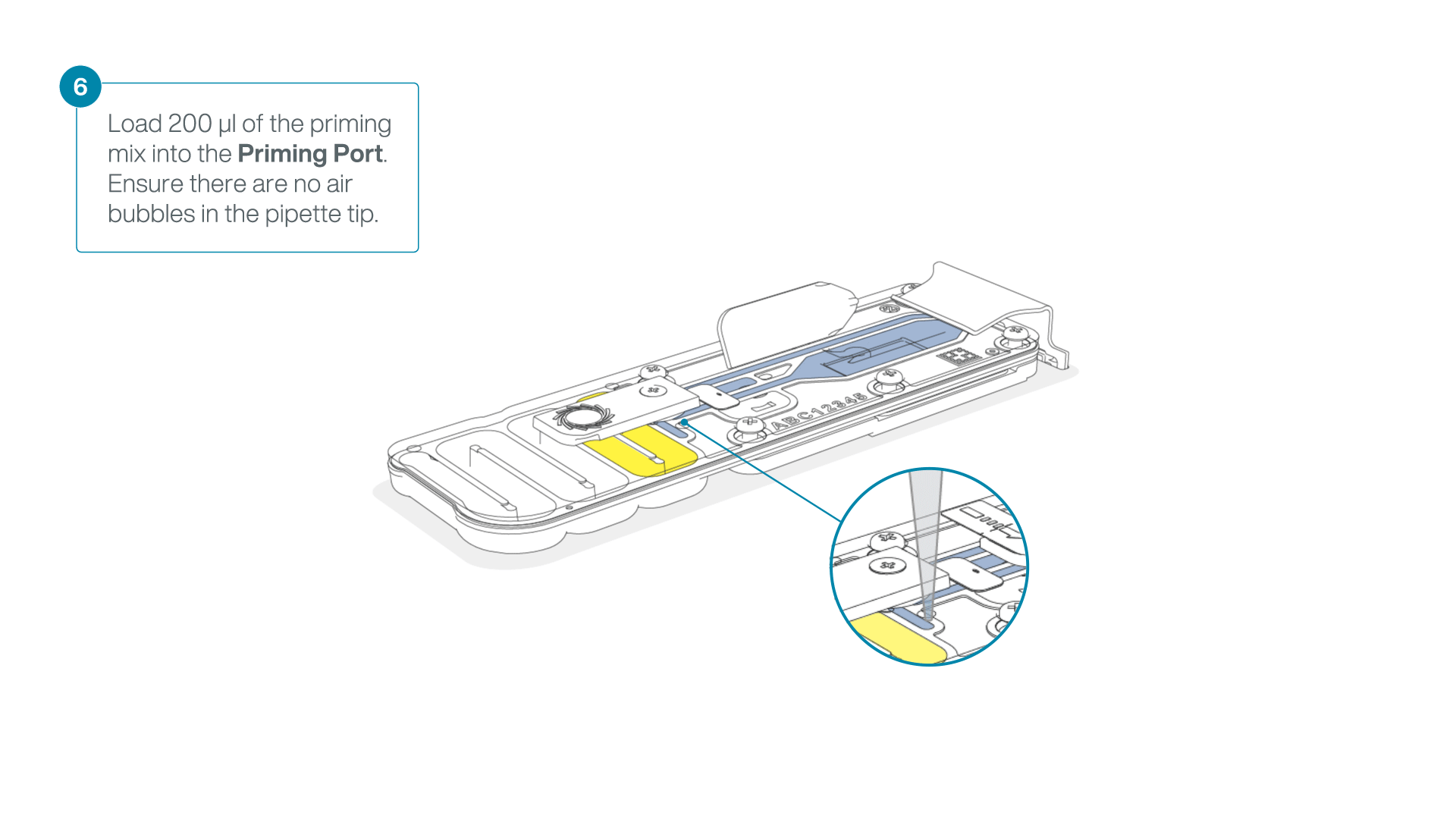
- Load 200 µl of the priming mix into the flow cell priming port (not the SpotON sample port), avoiding the introduction of air bubbles.

-
Mix the prepared library gently by pipetting up and down just prior to loading.
-
Add 75 μl of the prepared library to the flow cell via the SpotON sample port in a dropwise fashion. Ensure each drop flows into the port before adding the next.
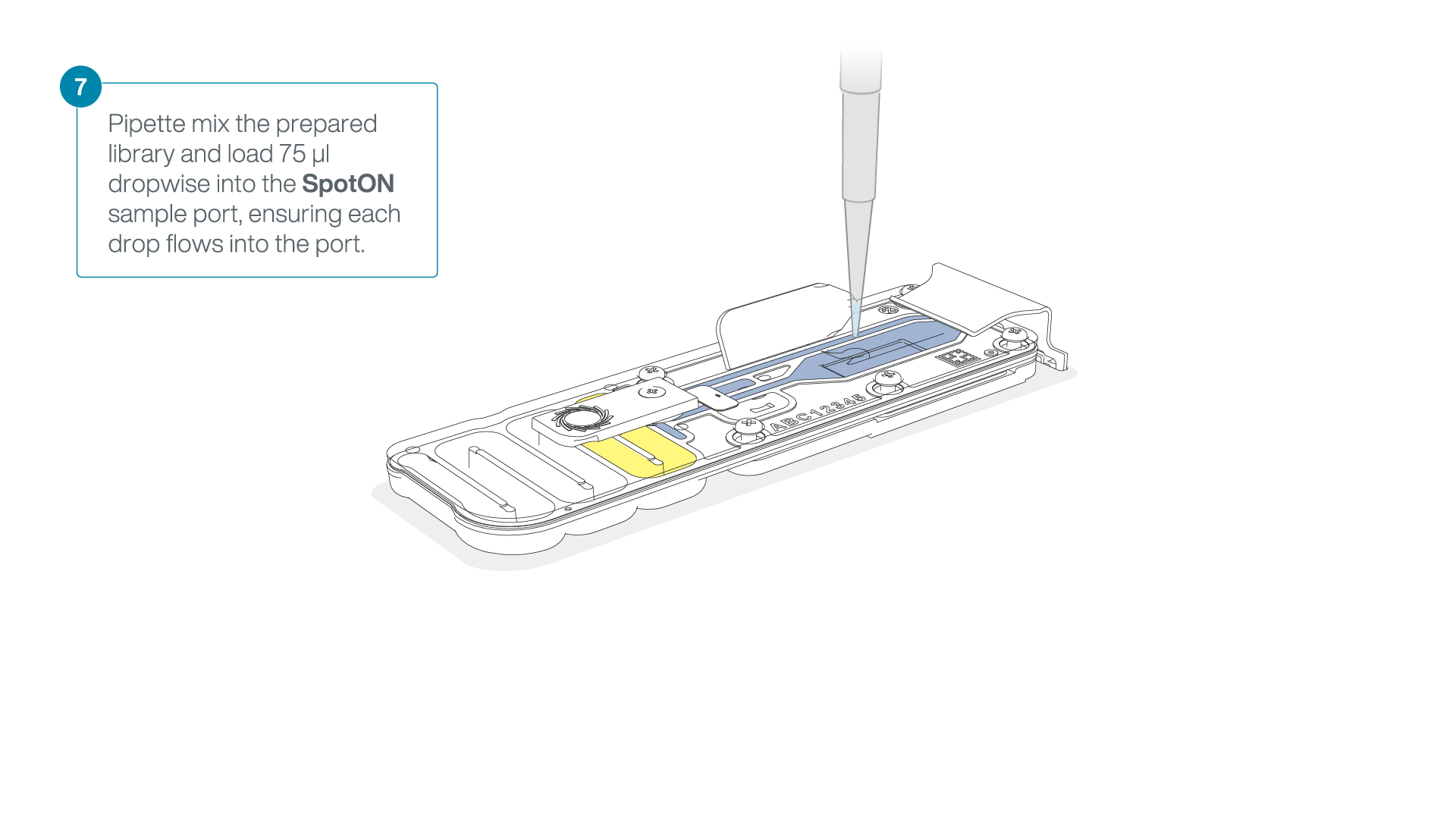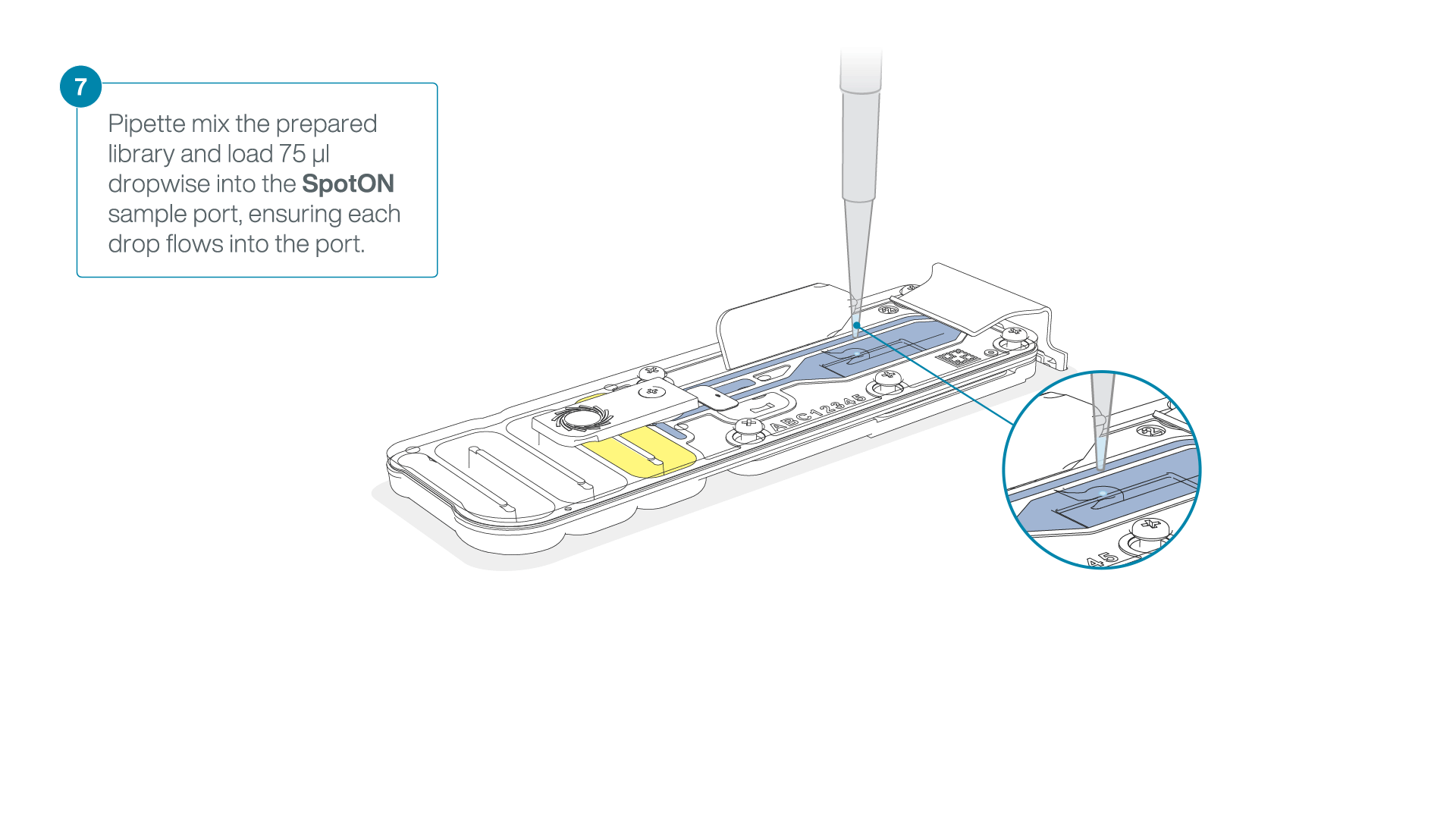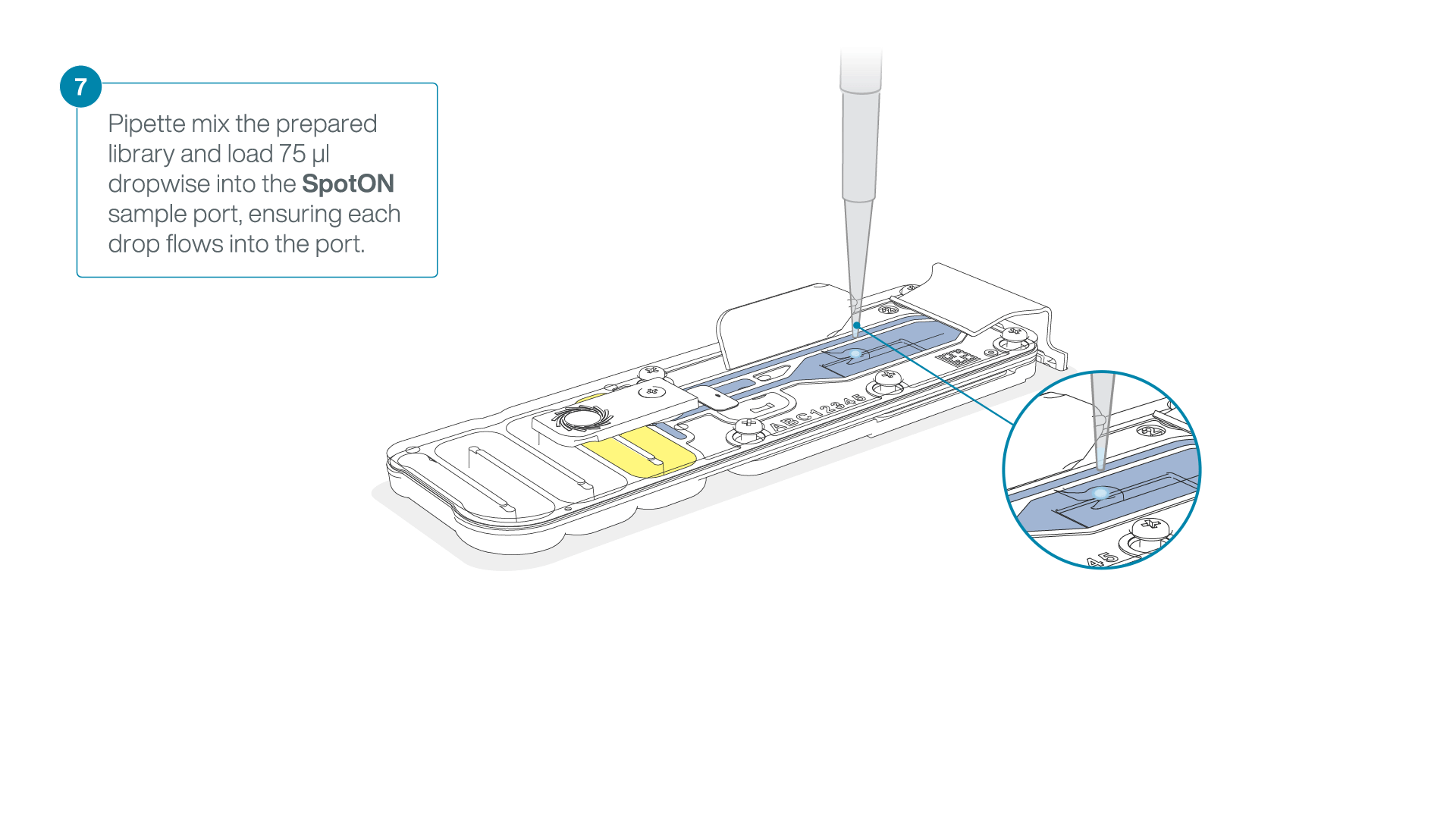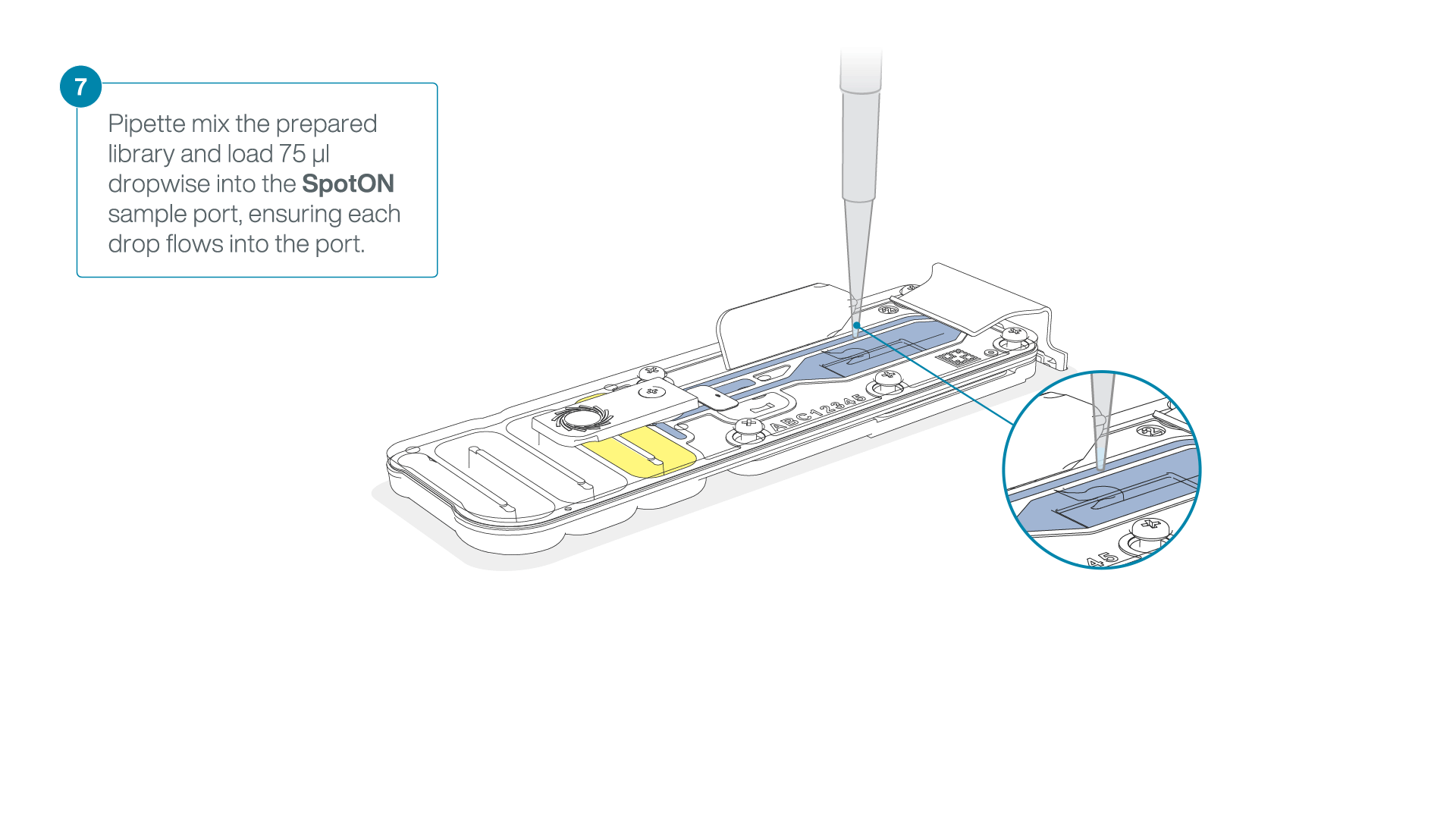
-
Gently replace the SpotON sample port cover, making sure the bung enters the SpotON port and close the priming port.


-
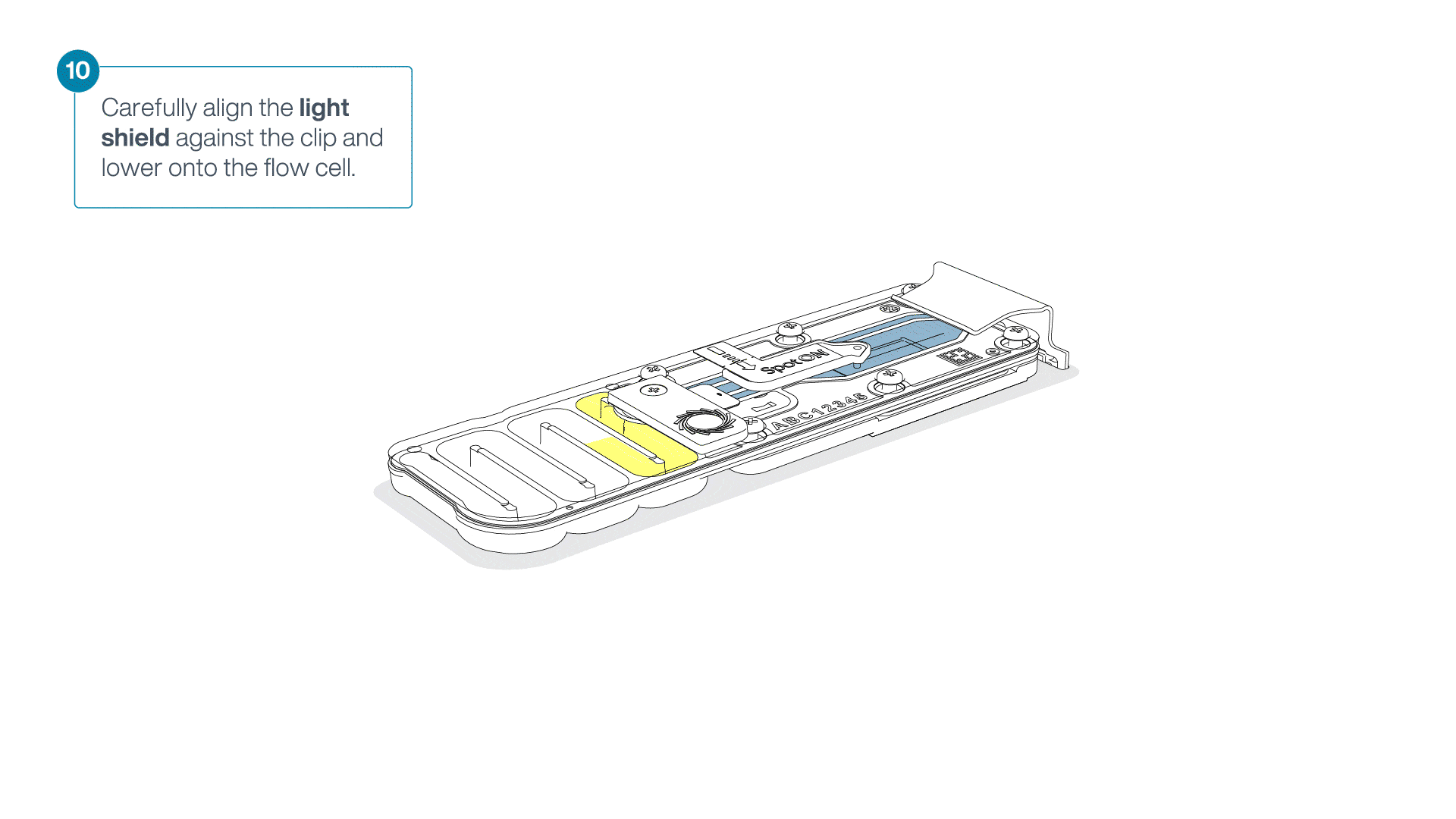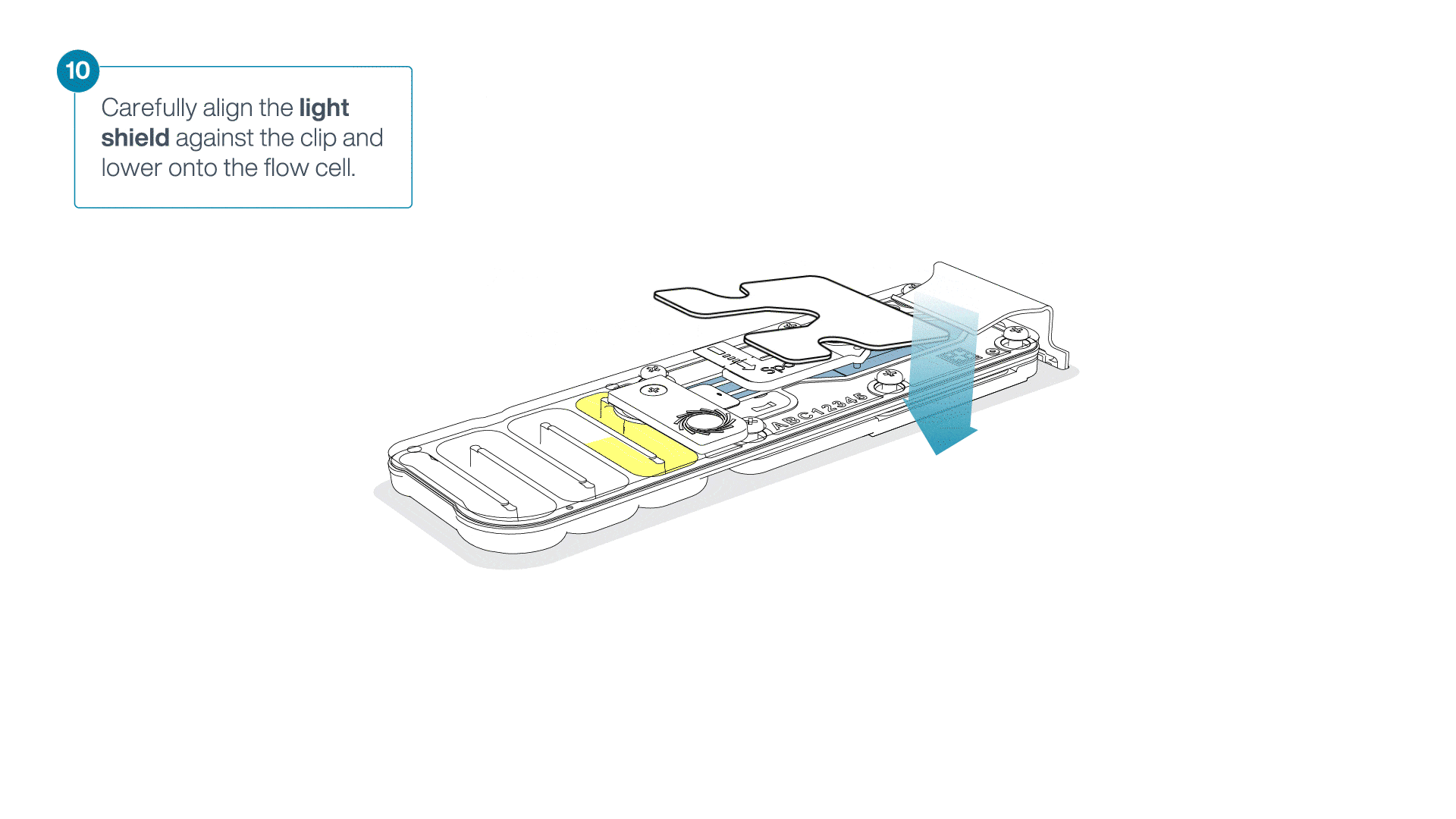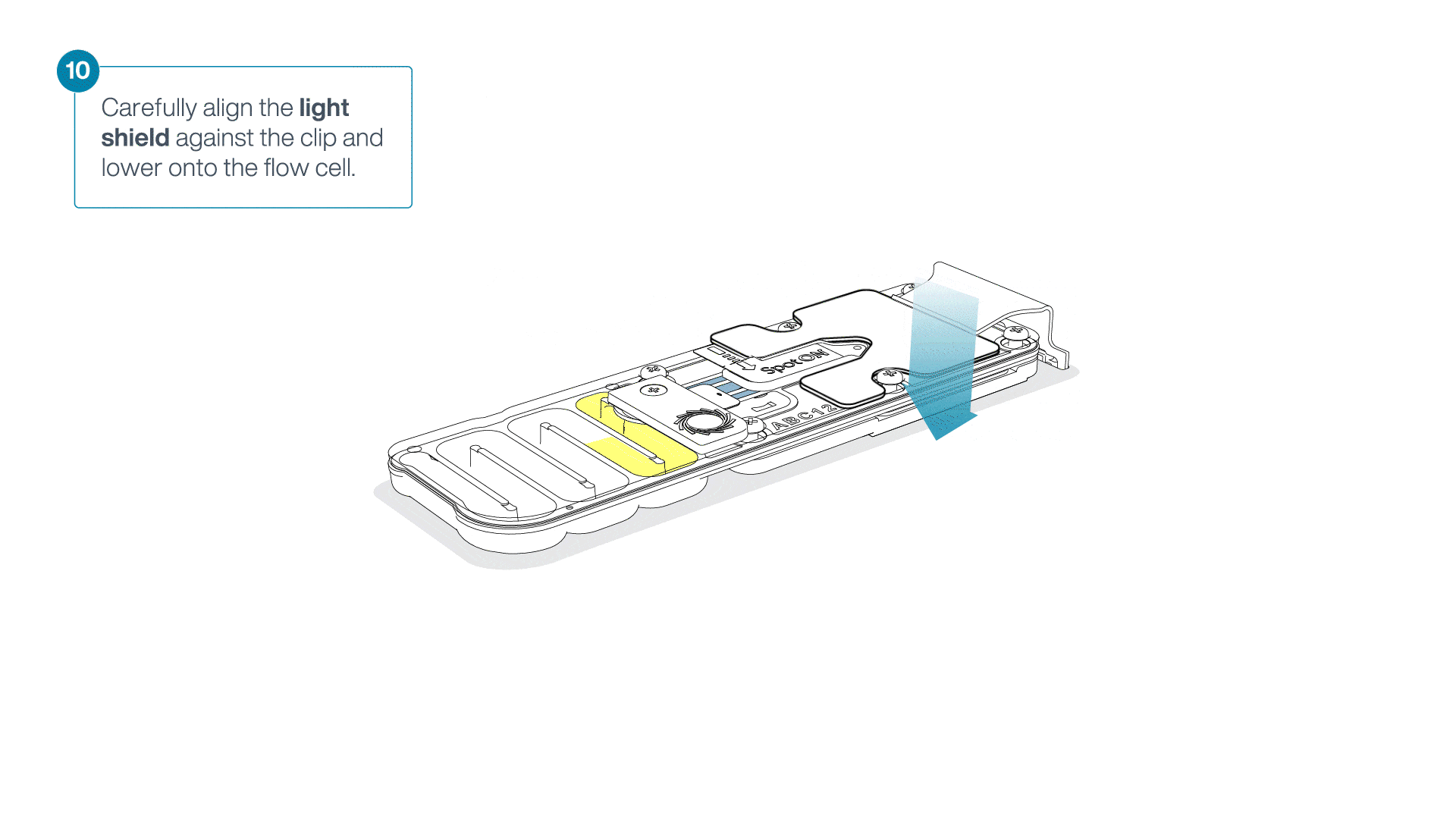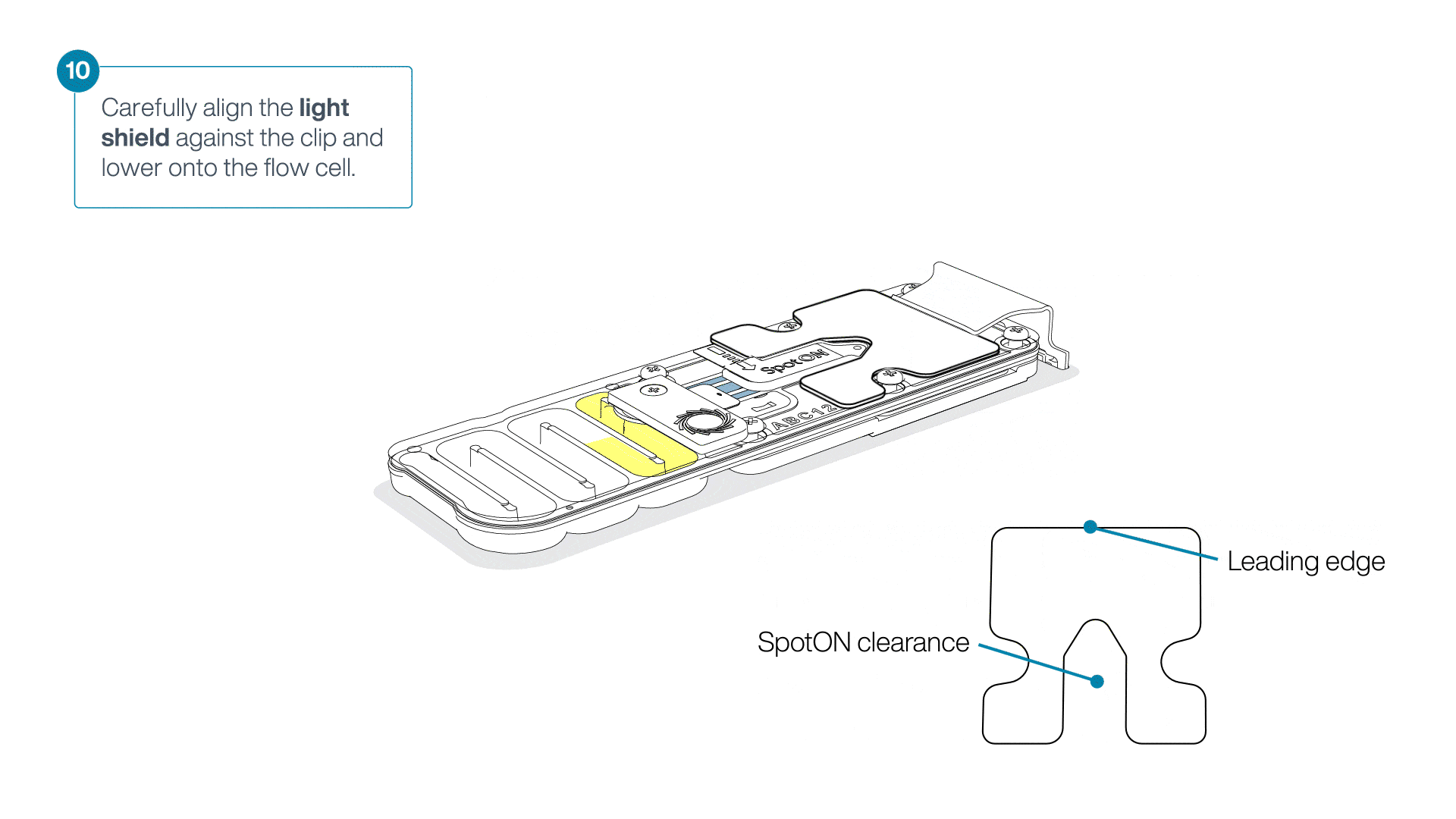
Place the light shield onto the flow cell, as follows:
Carefully place the leading edge of the light shield against the clip.
Note: Do not force the light shield underneath the clip.Gently lower the light shield onto the flow cell. The light shield should sit around the SpotON cover, covering the entire top section of the flow cell.











Sequencing and data analysis
Data acquisition and basecalling
Data acquisition and basecalling
-
Overview of nanopore data analysis
For a full overview of nanopore data analysis, which includes options for basecalling and post-basecalling analysis, please refer to the Data Analysis document.
-
How to start sequencing
The sequencing device control, data acquisition and real-time basecalling are carried out by the MinKNOW software. Please ensure MinKNOW is installed on your computer or device. There are multiple options for how to carry out sequencing:
1. Data acquisition and basecalling in real-time using MinKNOW on a computer
Follow the instructions in the MinKNOW protocol beginning from the "Starting a sequencing run" section until the end of the "Completing a MinKNOW run" section.
2. Data acquisition and basecalling in real-time using the MinION Mk1B/Mk1D device
Follow the instructions in the MinION Mk1B user manual or the MinION Mk1D user manual.
3. Data acquisition and basecalling in real-time using the MinION Mk1C device
Follow the instructions in the MinION Mk1C user manual.
4. Data acquisition and basecalling in real-time using the GridION device
Follow the instructions in the GridION user manual.
5. Data acquisition and basecalling in real-time using the PromethION device
Follow the instructions in the PromethION user manual or the PromethION 2 Solo user manual.
6. Data acquisition using MinKNOW on a computer and basecalling at a later time using MinKNOW
Follow the instructions in the MinKNOW protocol beginning from the "Starting a sequencing run" section until the end of the "Completing a MinKNOW run" section. When setting your experiment parameters, set the Basecalling tab to OFF. After the sequencing experiment has completed, follow the instructions in the Post-run analysis section of the MinKNOW protocol.
-
When setting the sequencing parameters in MinKNOW, in the Basecalling set barcoding as Enabled, and in the barcoding options, toggle Barcode both ends, Mid-read barcodes and Override minimum mid barcoding score to ON and set Minimum mid barcoding score to 50.
Optional: basecalling and/or demultiplexing of sequences can be performed using the stand-alone Guppy software.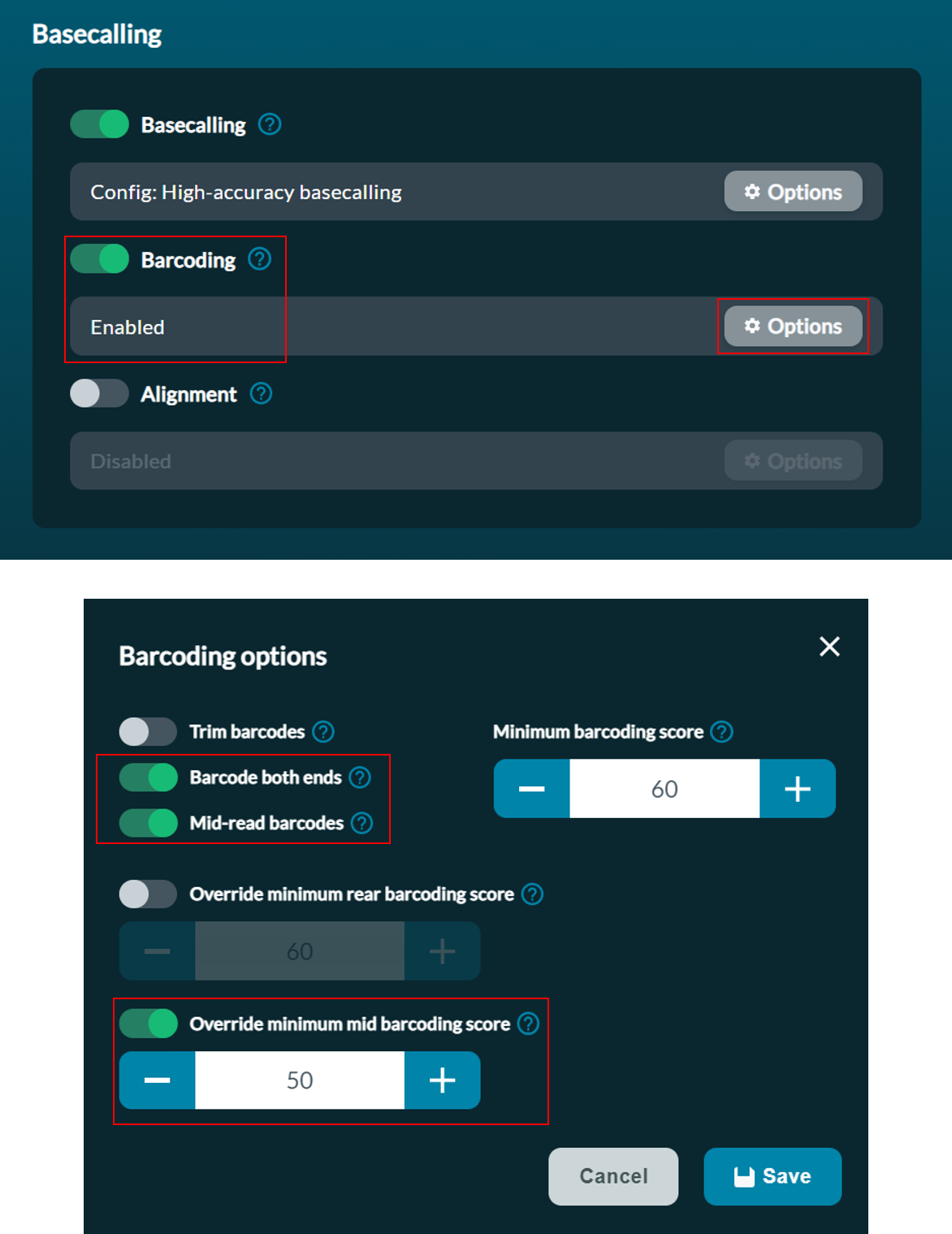

Downstream analysis and expected results
Downstream analysis and expected results
-
Recommended analysis pipeline
The recommended workflows for the bioinformatics analyses are provided by the ARTIC network and are documented on their web pages at https://artic.network/ncov-2019/ncov2019-bioinformatics-sop.html.
The reference guided genome assembly and variant calling are also performed according to the bioinformatics protocol provided by the ARTIC network. Their best practices guide uses the software contained within the FieldBioinformatics project on GitHub.
This workflow uses only the basecalled FASTQ files to perform a high-quality reference-guided assembly of the SARS-CoV-2 genome. Sequenced reads are re-demultiplexed with the requirement that reads must contain a barcode at both ends of the sequence (this only applies to the Classic and Eco PCR tiling of SARS-CoV-2 protocols but not the Rapid Barcoding PCR tiling of SARS-CoV-2), and must not contain internal barcodes. The reads are mapped to the reference genome, primer sequences are excluded and the consensus sequence is polished. The Medaka software is used to call single-nucleotide variants while the ARTIC software reports the high-quality consensus sequence from the workflow.
-
Expected results
Here, results are shown based on human coronavirus 229E spiked into 100 ng of human RNA derived from GM12878 cell line. 10 pg–0.001 pg of viral RNA obtained from ATCC was spiked into the human RNA and human-only and reverse transcription negative controls were carried through the prep to sequencing. Every sample underwent 30 and 35 cycles of PCR to determine sensitivity and specificity guidelines, as well as the expected amplicon drop-out rate for each sample.
Note: The viral RNA from ATCC is generated from cell lines infected with human coronavirus 229E. The RNA supplied is total RNA extracted from the cell lines and includes both human and viral RNA. Therefore, the levels of sensitivity are likely to be higher than those reported here.
-
Sample balancing
The graph below shows the expected sequence balancing if the protocol is followed. Here, equal masses went into the end-prep and native barcode ligation prior to pooling by equal mass for adapter ligation.
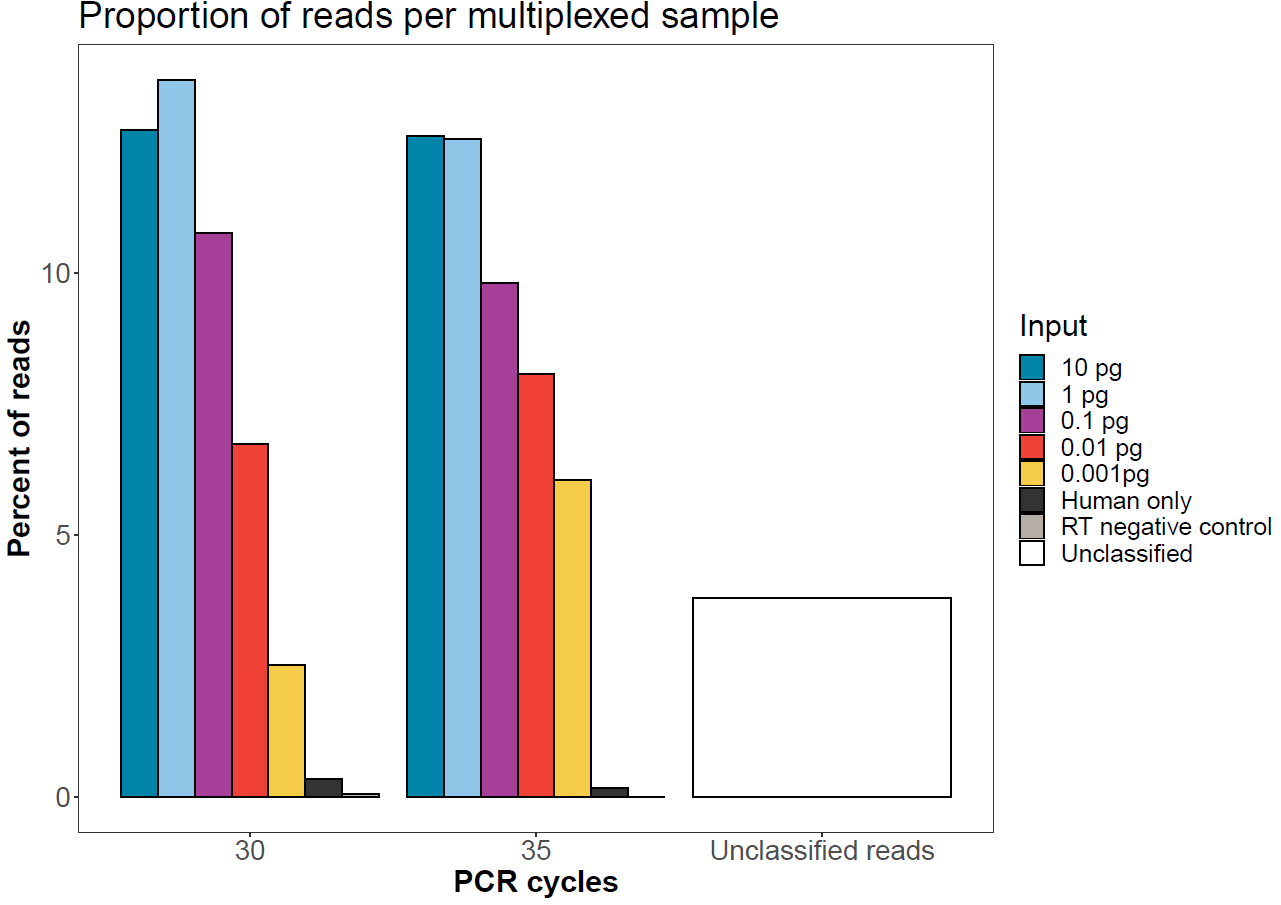
Figure 3. Number of reads per sample after native barcode demultiplexing in MinKNOW. All 14 samples were run on a single flow cell. -
On-target rate
Sequences from each demultiplexed sample were aligned to the human coronavirus 229E genome using minimap2. The proportion of primary alignments per sample are reported below.
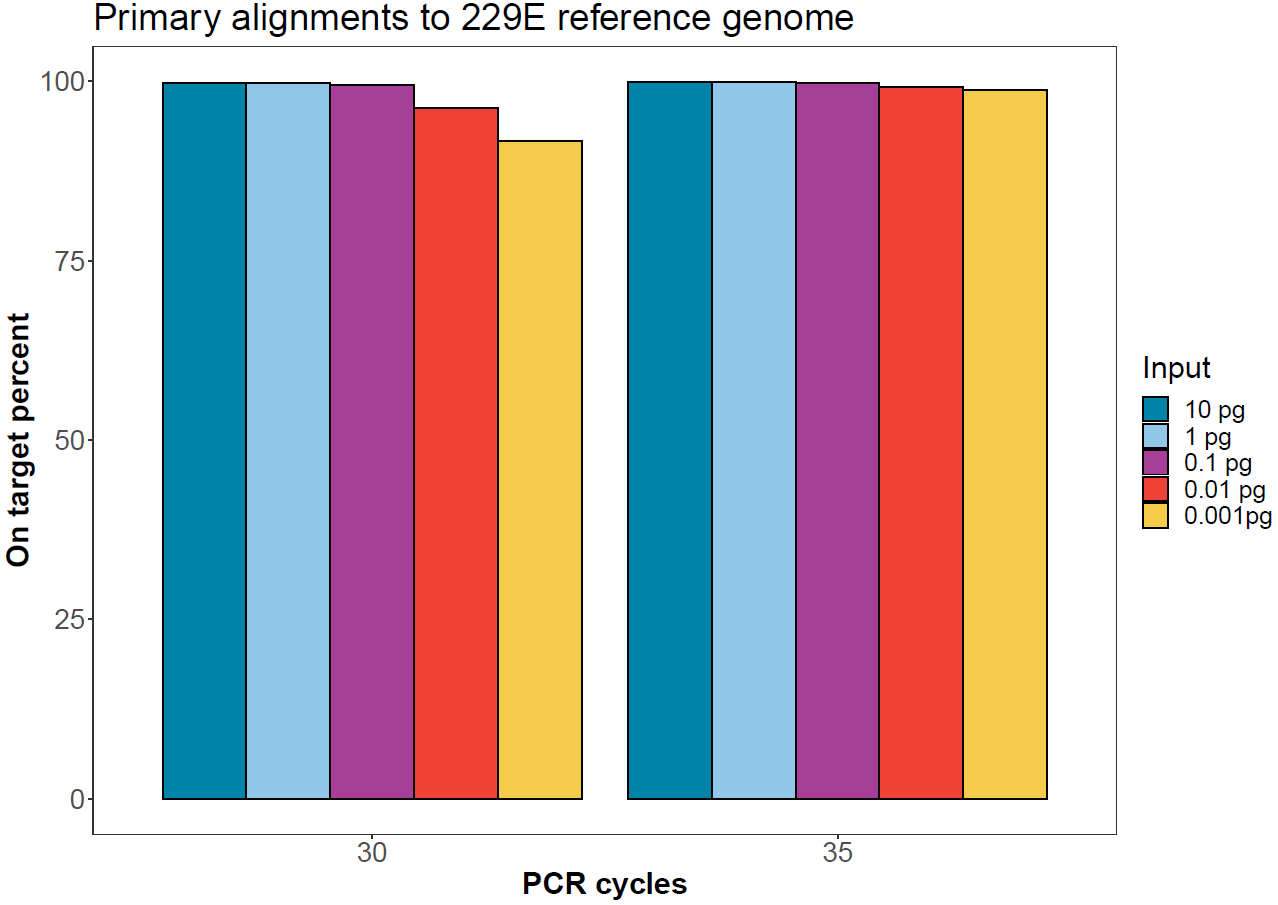
Figure 4. Proportion of reads for each sample aligning to the human coronavirus 229E reference genome. -
Assessment of negative controls
After 12 hours of sequencing, the number of reads from the negative control samples aligning to the viral reference genome is shown in the graph below and is compared with the absolute number of sequences aligning to the lowest input (0.001 pg).
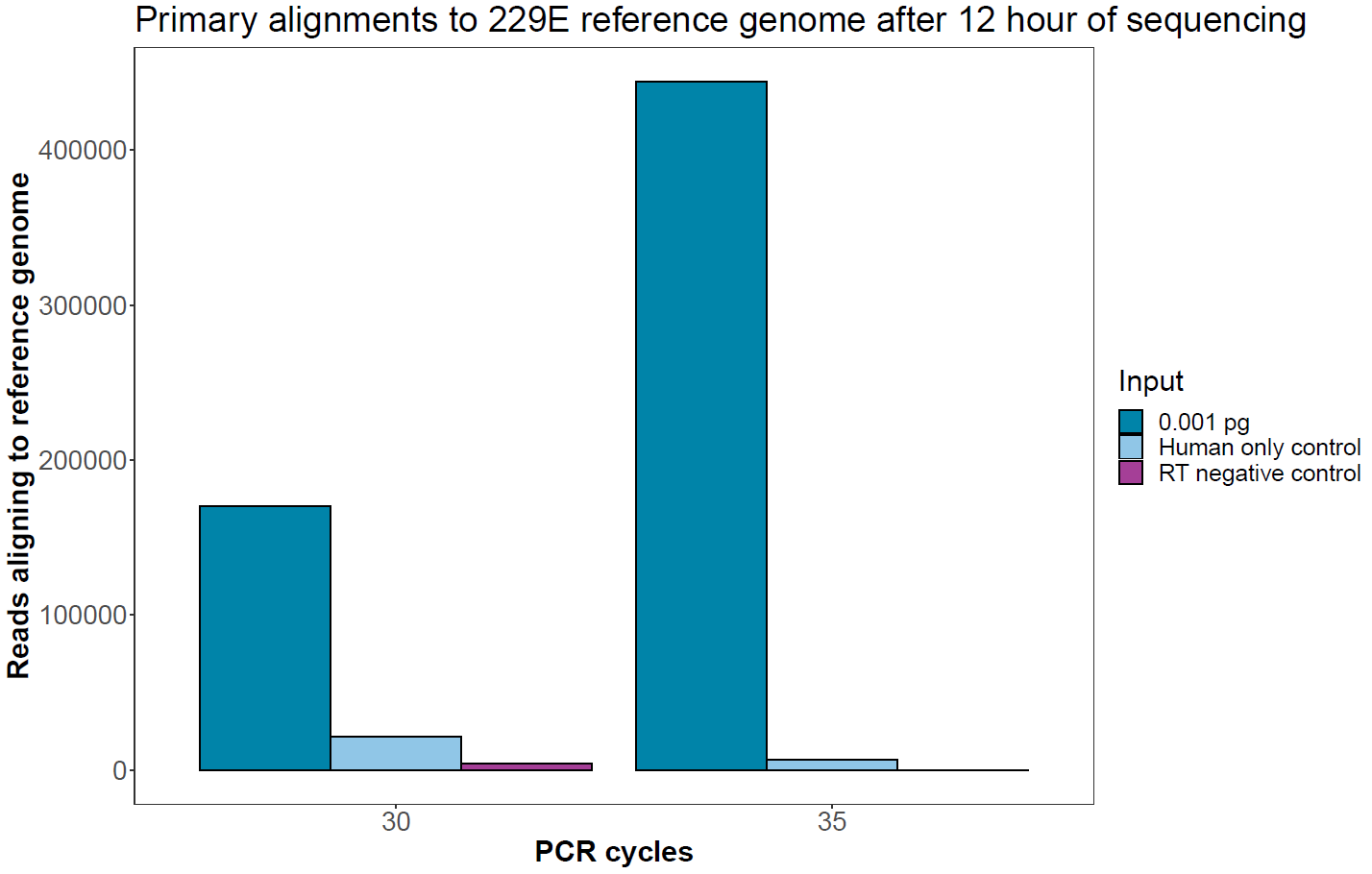
Figure 5. Absolute number of reads aligning to the human coronavirus 229E reference genome in the negative controls compared with the lowest input of viral RNA. Sequencing was carried out for 12 hours to pick up low levels of sequences assigned to barcodes representing these samples. -
Target coverage for different PCR cycles and viral load
To assess the impact of PCR dropout with lowering input viral load and increasing PCR cycles, Mosdepth was used to calculate the proportion of the viral genome covered to different depth levels. These numbers were calculated after 12 hours of sequencing with 14 samples multiplexed.
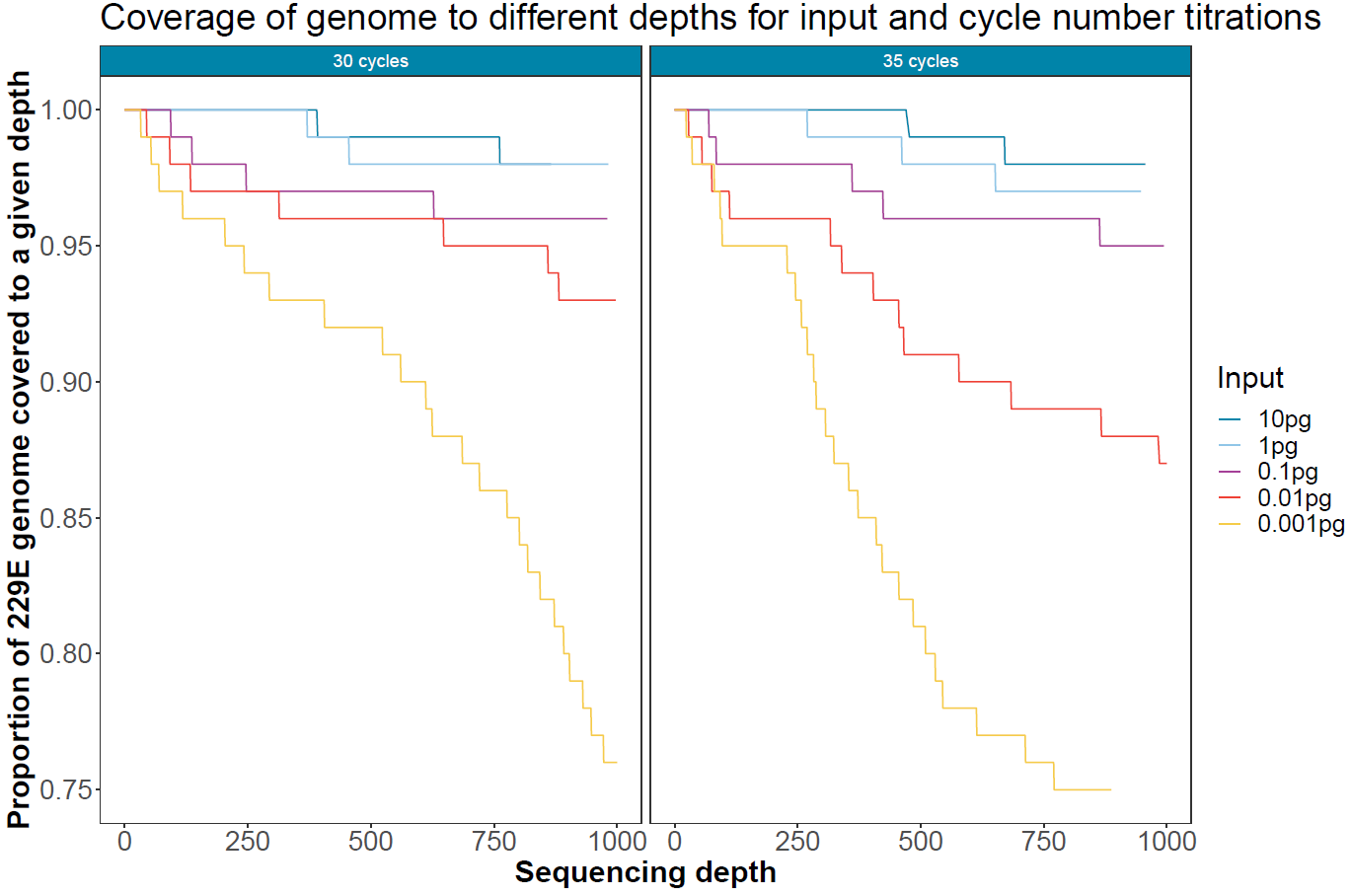
Figure 6. Coverage and depth of the human coronavirus 229E genome for different input quantities of viral RNA and different cycle numbers after 12 hours of sequencing on a single flow cell. -
How much sequencing is required?
This is unknown in real clinical samples. The graph below can be used to determine the proportion of the genome that could be covered to a given depth with different numbers of reads (30 cycles) at different input amounts in a background of 100 ng human RNA.
Note: this is absolute depth.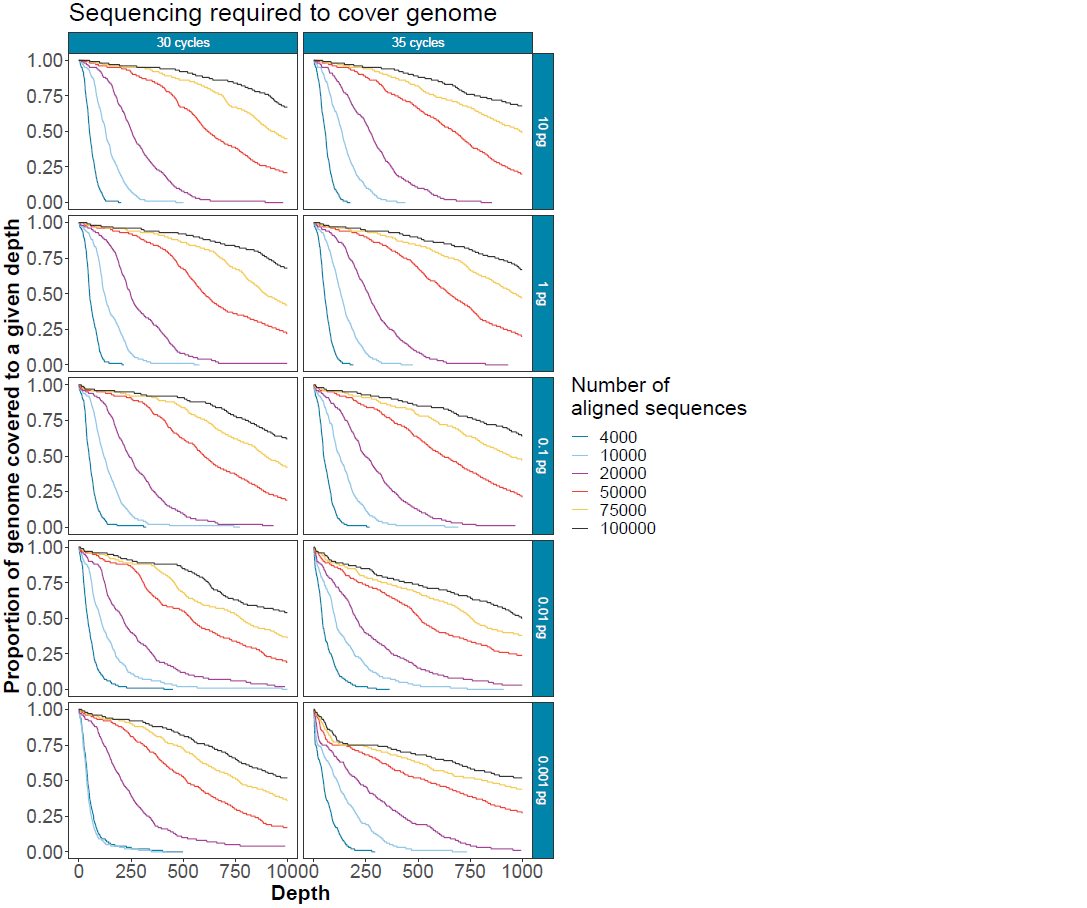
Figure 7. Subsampled sequences to give an indication of the depth of sequencing achievable covering different amounts of the human coronavirus 229E genome. Input quantities and cycle number titrations show that high cycle numbers should be avoided where possible to minimise amplicon drop out.This protocol provides amplification of low copy number viral genomes in a tiled method with low off-target amplification and minimal cross-contamination between samples. With <60 copies per reaction (0.001 pg viral input) in 100 ng background human RNA, under ideal circumstances, one should expect to cover >75% of the targeted genome at a depth of 200X within under 50,000 reads in the samples with the lowest viral titre and <20,000 reads in those with a higher viral titre.





Flow cell reuse and returns
Flow cell reuse and returns
- Materials
-
- Flow Cell Wash Kit (EXP-WSH004)
-
After your sequencing experiment is complete, if you would like to reuse the flow cell, please follow the Flow Cell Wash Kit protocol and store the washed flow cell at +2°C to +8°C.
The Flow Cell Wash Kit protocol is available on the Nanopore Community.
-
Alternatively, follow the returns procedure to send the flow cell back to Oxford Nanopore.
Instructions for returning flow cells can be found here.
Troubleshooting
Issues during automation of library preparation
Issues during automation of library preparation
-
Please contact your automation vendor FAS and/or Nanopore FAS if you have any issues.
Issues during the sequencing run
Issues during the sequencing run
-
Below is a list of the most commonly encountered issues, with some suggested causes and solutions.
We also have an FAQ section available on the Nanopore Community Support section.
If you have tried our suggested solutions and the issue still persists, please contact Technical Support via email (support@nanoporetech.com) or via LiveChat in the Nanopore Community.
-
Fewer pores at the start of sequencing than after Flow Cell Check
Observation Possible cause Comments and actions MinKNOW reported a lower number of pores at the start of sequencing than the number reported by the Flow Cell Check An air bubble was introduced into the nanopore array After the Flow Cell Check it is essential to remove any air bubbles near the priming port before priming the flow cell. If not removed, the air bubble can travel to the nanopore array and irreversibly damage the nanopores that have been exposed to air. The best practice to prevent this from happening is demonstrated in this video. MinKNOW reported a lower number of pores at the start of sequencing than the number reported by the Flow Cell Check The flow cell is not correctly inserted into the device Stop the sequencing run, remove the flow cell from the sequencing device and insert it again, checking that the flow cell is firmly seated in the device and that it has reached the target temperature. If applicable, try a different position on the device (GridION/PromethION). MinKNOW reported a lower number of pores at the start of sequencing than the number reported by the Flow Cell Check Contaminations in the library damaged or blocked the pores The pore count during the Flow Cell Check is performed using the QC DNA molecules present in the flow cell storage buffer. At the start of sequencing, the library itself is used to estimate the number of active pores. Because of this, variability of about 10% in the number of pores is expected. A significantly lower pore count reported at the start of sequencing can be due to contaminants in the library that have damaged the membranes or blocked the pores. Alternative DNA/RNA extraction or purification methods may be needed to improve the purity of the input material. The effects of contaminants are shown in the Contaminants Know-how piece. Please try an alternative extraction method that does not result in contaminant carryover. -
MinKNOW script failed
Observation Possible cause Comments and actions MinKNOW shows "Script failed" Restart the computer and then restart MinKNOW. If the issue persists, please collect the MinKNOW log files and contact Technical Support. If you do not have another sequencing device available, we recommend storing the flow cell and the loaded library at 4°C and contact Technical Support for further storage guidance. -
Pore occupancy below 40%
Observation Possible cause Comments and actions Pore occupancy <40% Not enough library was loaded on the flow cell Ensure you load the recommended amount of good quality library in the relevant library prep protocol onto your flow cell. Please quantify the library before loading and calculate mols using tools like the Promega Biomath Calculator, choosing "dsDNA: µg to pmol" Pore occupancy close to 0 The Ligation Sequencing Kit was used, and sequencing adapters did not ligate to the DNA Make sure to use the NEBNext Quick Ligation Module (E6056) and Oxford Nanopore Technologies Ligation Buffer (LNB, provided in the sequencing kit) at the sequencing adapter ligation step, and use the correct amount of each reagent. A Lambda control library can be prepared to test the integrity of the third-party reagents. Pore occupancy close to 0 The Ligation Sequencing Kit was used, and ethanol was used instead of LFB or SFB at the wash step after sequencing adapter ligation Ethanol can denature the motor protein on the sequencing adapters. Make sure the LFB or SFB buffer was used after ligation of sequencing adapters. Pore occupancy close to 0 No tether on the flow cell Tethers are adding during flow cell priming (FLT/FCT tube). Make sure FLT/FCT was added to FB/FCF before priming. -
Shorter than expected read length
Observation Possible cause Comments and actions Shorter than expected read length Unwanted fragmentation of DNA sample Read length reflects input DNA fragment length. Input DNA can be fragmented during extraction and library prep.
1. Please review the Extraction Methods in the Nanopore Community for best practice for extraction.
2. Visualise the input DNA fragment length distribution on an agarose gel before proceeding to the library prep.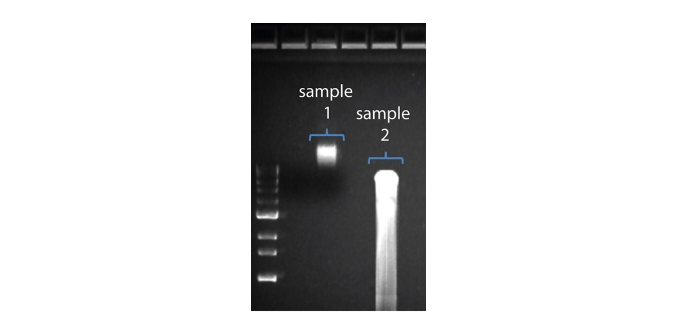 In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented.
In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented.
3. During library prep, avoid pipetting and vortexing when mixing reagents. Flicking or inverting the tube is sufficient. -
Large proportion of unavailable pores
Observation Possible cause Comments and actions Large proportion of unavailable pores (shown as blue in the channels panel and pore activity plot) 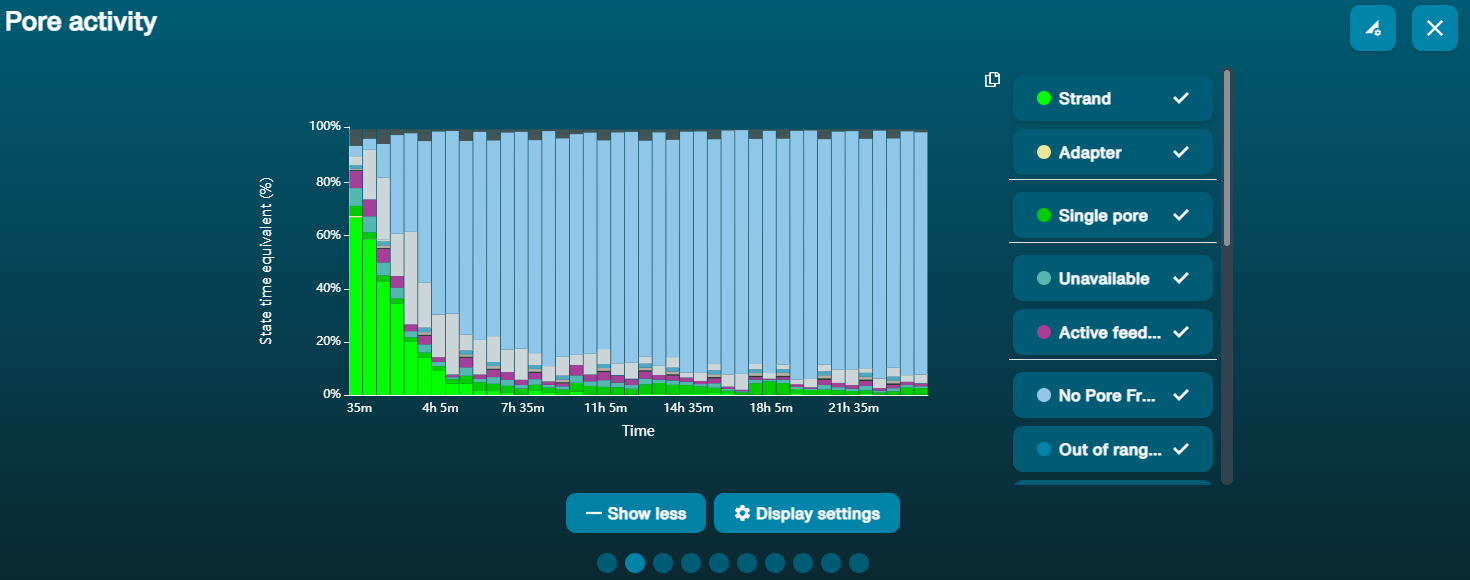 The pore activity plot above shows an increasing proportion of "unavailable" pores over time.
The pore activity plot above shows an increasing proportion of "unavailable" pores over time.Contaminants are present in the sample Some contaminants can be cleared from the pores by the unblocking function built into MinKNOW. If this is successful, the pore status will change to "sequencing pore". If the portion of unavailable pores stays large or increases:
1. A nuclease flush using the Flow Cell Wash Kit (EXP-WSH004) can be performed, or
2. Run several cycles of PCR to try and dilute any contaminants that may be causing problems. -
Large proportion of inactive pores
Observation Possible cause Comments and actions Large proportion of inactive/unavailable pores (shown as light blue in the channels panel and pore activity plot. Pores or membranes are irreversibly damaged) Air bubbles have been introduced into the flow cell Air bubbles introduced through flow cell priming and library loading can irreversibly damage the pores. Watch the Priming and loading your flow cell video for best practice Large proportion of inactive/unavailable pores Certain compounds co-purified with DNA Known compounds, include polysaccharides, typically associate with plant genomic DNA.
1. Please refer to the Plant leaf DNA extraction method.
2. Clean-up using the QIAGEN PowerClean Pro kit.
3. Perform a whole genome amplification with the original gDNA sample using the QIAGEN REPLI-g kit.Large proportion of inactive/unavailable pores Contaminants are present in the sample The effects of contaminants are shown in the Contaminants Know-how piece. Please try an alternative extraction method that does not result in contaminant carryover. -
Reduction in sequencing speed and q-score later into the run
Observation Possible cause Comments and actions Reduction in sequencing speed and q-score later into the run For Kit 9 chemistry (e.g. SQK-LSK109), fast fuel consumption is typically seen when the flow cell is overloaded with library (please see the appropriate protocol for your DNA library to see the recommendation). Add more fuel to the flow cell by following the instructions in the MinKNOW protocol. In future experiments, load lower amounts of library to the flow cell. -
Temperature fluctuation
Observation Possible cause Comments and actions Temperature fluctuation The flow cell has lost contact with the device Check that there is a heat pad covering the metal plate on the back of the flow cell. Re-insert the flow cell and press it down to make sure the connector pins are firmly in contact with the device. If the problem persists, please contact Technical Services. -
Failed to reach target temperature
Observation Possible cause Comments and actions MinKNOW shows "Failed to reach target temperature" The instrument was placed in a location that is colder than normal room temperature, or a location with poor ventilation (which leads to the flow cells overheating) MinKNOW has a default timeframe for the flow cell to reach the target temperature. Once the timeframe is exceeded, an error message will appear and the sequencing experiment will continue. However, sequencing at an incorrect temperature may lead to a decrease in throughput and lower q-scores. Please adjust the location of the sequencing device to ensure that it is placed at room temperature with good ventilation, then re-start the process in MinKNOW. Please refer to this link for more information on MinION temperature control. -
Guppy – no input .fast5 was found or basecalled
Observation Possible cause Comments and actions No input .fast5 was found or basecalled input_path did not point to the .fast5 file location The --input_path has to be followed by the full file path to the .fast5 files to be basecalled, and the location has to be accessible either locally or remotely through SSH. No input .fast5 was found or basecalled The .fast5 files were in a subfolder at the input_path location To allow Guppy to look into subfolders, add the --recursive flag to the command -
Guppy – no Pass or Fail folders were generated after basecalling
Observation Possible cause Comments and actions No Pass or Fail folders were generated after basecalling The --qscore_filtering flag was not included in the command The --qscore_filtering flag enables filtering of reads into Pass and Fail folders inside the output folder, based on their strand q-score. When performing live basecalling in MinKNOW, a q-score of 7 (corresponding to a basecall accuracy of ~80%) is used to separate reads into Pass and Fail folders. -
Guppy – unusually slow processing on a GPU computer
Observation Possible cause Comments and actions Unusually slow processing on a GPU computer The --device flag wasn't included in the command The --device flag specifies a GPU device to use for accelerate basecalling. If not included in the command, GPU will not be used. GPUs are counted from zero. An example is --device cuda:0 cuda:1, when 2 GPUs are specified to use by the Guppy command.
 In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented.
In the image above, Sample 1 is of high molecular weight, whereas Sample 2 has been fragmented. The pore activity plot above shows an increasing proportion of "unavailable" pores over time.
The pore activity plot above shows an increasing proportion of "unavailable" pores over time.Become a full member
Purchase a MinION Starter Pack from Avantor to get full community access and benefit from:
- News - hear about the latest product updates
- Posts - interact with thousands of nanopore users from around the globe
- Software - download the latest sequencing and analysis software
Already have a Nanopore Community account?
Log in hereNeed more help?
Request a call with our experts for detailed advice on implementing nanopore sequencing.
Request a callInterested in microbiology?
Visit our microbial sequencing spotlight page on vwr.com.
Microbial sequencing