- Materials
-
- Input influenza RNA
- Influenza A primers
- Influenza B primers
- Ligation Sequencing Kit (SQK-LSK109)
- Native Barcoding Expansion 96 (EXP-NBD196)
- Or Native Barcoding Expansion 1-12 (EXP-NBD104) and 13-24 (EXP-NBD114) if multiplexing 1-24 samples.
- Flow Cell Priming Kit (EXP-FLP002)
- Adapter Mix II Expansion (EXP-AMII001)
- SFB Expansion (EXP-SFB001)
- Sequencing Auxiliary Vials (EXP-AUX001)
- Consumables
-
- SuperScript III One-Step RT-PCR System with Platinum Taq DNA Polymerase (ThermoFisher, cat # 12574018 or 12574026)
- Nuclease-free water (e.g. ThermoFisher, AM9937)
- Agencourt AMPure XP beads (Beckman Coulter, A63881)
- Freshly prepared 80% ethanol in nuclease-free water
- NEB Blunt/TA Ligase Master Mix (NEB, M0367)
- NEBNext Ultra II End repair/dA-tailing Module (NEB, E7546)
- NEBNext Quick Ligation Module (NEB, E6056)
- 1.5 ml Eppendorf DNA LoBind tubes
- 5 ml Eppendorf DNA LoBind tubes
- 15 ml Eppendorf DNA LoBind tubes
- Reagent reservoirs for multichannel pipetting
- Qubit dsDNA HS Assay Kit (Invitrogen, Q32851)
- Qubit™ Assay Tubes (Invitrogen, Q32856)
- Eppendorf twin.tec® PCR plate 96 LoBind, semi-skirted (Cat # 0030129504) with heat seals
- Equipment
-
- Magnetic rack, suitable for 1.5 ml Eppendorf tubes
- Magnetic rack suitable for 96 well plates, e.g. DynaMag™-96 Side Skirted Magnet (Thermo Fisher CAT#12027)
- Microfuge
- Vortex mixer
- Thermal cycler
- Hula mixer (gentle rotator mixer)
- Microplate centrifuge, e.g. Fisherbrand™ Mini Plate Spinner Centrifuge (Fisher Scientific, 11766427)
- Qubit fluorometer (or equivalent for QC check)
- Multichannel pipettes suitable for dispensing 0.5–10 μl, 2–20 μl and 20–200 μl, and tips
- P1000 pipette and tips
- P200 pipette and tips
- P100 pipette and tips
- P20 pipette and tips
- P10 pipette and tips
- P2 pipette and tips
- Ice bucket with ice
- Timer
- Optional equipment
-
- PCR hoods with UV steriliser
- PCR-Cooler (Eppendorf)
- Eppendorf 5424 centrifuge (or equivalent)
-
Ligation Sequencing Kit (SQK-LSK109) contents

Name Acronym Cap colour No. of vials Fill volume per vial (µl) DNA CS DCS Yellow 1 50 Adapter Mix AMX Green 1 40 Ligation Buffer LNB Clear 1 200 L Fragment Buffer LFB White cap, orange stripe on label 2 1,800 S Fragment Buffer SFB Grey 2 1,800 Sequencing Buffer SQB Red 2 300 Elution Buffer EB Black 1 200 Loading Beads LB Pink 1 360 -
Flow Cell Priming Kit (EXP-FLP002) contents
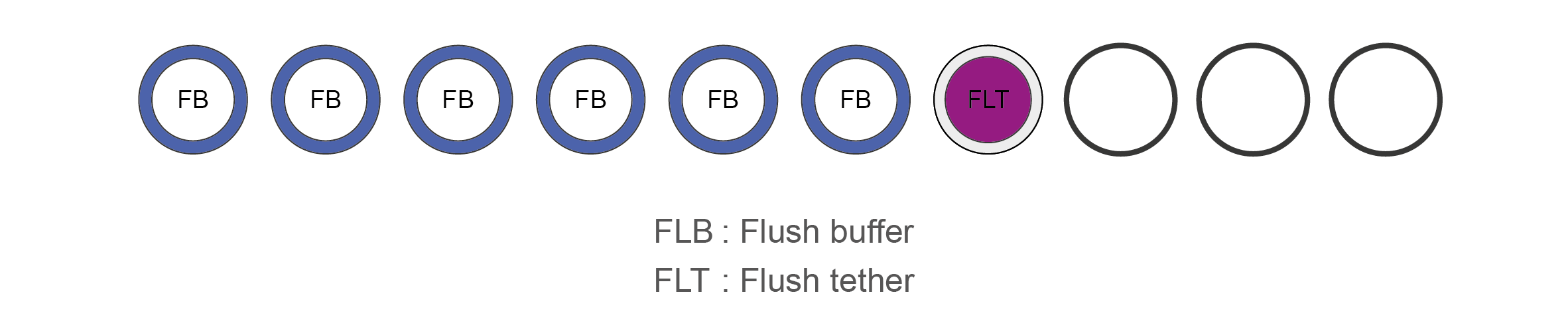
Name Acronym Cap colour No. of vial Fill volume per vial (μl) Flush Buffer FB Blue 6 1,170 Flush Tether FLT Purple 1 200 -
Native Barcoding Expansion 96 (EXP-NBD196) contents
Kits in batches NBD196.10.0007 onwards have barcodes ordered in columns on the plate:

Kits in batches prior to NBD196.10.0007 have barcodes ordered in rows:

Name Acronym Cap colour No. of vials Fill volume per vial (μl) Native Barcode 01-96 NB01-96 - 1 plate 40 μl per well Adapter Mix II AMII Green 1 70 -
SFB Expansion contents (EXP-SFB001)

Name Acronym Cap colour No. of vials Fill volume per vial (μl) Short Fragment Buffer SFB Grey 4 1,800 -
Adapter Mix II Expansion contents (EXP-AMII001)

Name Acronym Cap colour No. of tubes Fill volume per vial (μl) Adapter Mix II AMII Green 2 40 -
Adapter Mix II Expansion use
Protocols that use the Native Barcoding Expansions require 5 μl of AMII per reaction. Native Barcoding Expansions EXP-NBD104/NBD114 contain sufficient AMII for 6 reactions (or 12 reactions when sequencing on Flongle). This assumes that all barcodes are used in one sequencing run.
The Adapter Mix II expansion provides additional AMII for customers who are running subsets of barcodes, and allows a further 12 reactions (24 on Flongle).
-
Sequencing Auxiliary Vials contents (EXP-AUX001)

Name Acronym Cap colour No. of vials Fill volume per vial (μl) Sequencing Buffer SQB Red 6 300 Elution Buffer EB Black 2 200 Loading Beads LB Pink 2 360 -
Native barcode sequences
Component Forward sequence Reverse sequence NB01 CACAAAGACACCGACAACTTTCTT AAGAAAGTTGTCGGTGTCTTTGTG NB02 ACAGACGACTACAAACGGAATCGA TCGATTCCGTTTGTAGTCGTCTGT NB03 CCTGGTAACTGGGACACAAGACTC GAGTCTTGTGTCCCAGTTACCAGG NB04 TAGGGAAACACGATAGAATCCGAA TTCGGATTCTATCGTGTTTCCCTA NB05 AAGGTTACACAAACCCTGGACAAG CTTGTCCAGGGTTTGTGTAACCTT NB06 GACTACTTTCTGCCTTTGCGAGAA TTCTCGCAAAGGCAGAAAGTAGTC NB07 AAGGATTCATTCCCACGGTAACAC GTGTTACCGTGGGAATGAATCCTT NB08 ACGTAACTTGGTTTGTTCCCTGAA TTCAGGGAACAAACCAAGTTACGT NB09 AACCAAGACTCGCTGTGCCTAGTT AACTAGGCACAGCGAGTCTTGGTT NB10 GAGAGGACAAAGGTTTCAACGCTT AAGCGTTGAAACCTTTGTCCTCTC NB11 TCCATTCCCTCCGATAGATGAAAC GTTTCATCTATCGGAGGGAATGGA NB12 TCCGATTCTGCTTCTTTCTACCTG CAGGTAGAAAGAAGCAGAATCGGA NB13 AGAACGACTTCCATACTCGTGTGA TCACACGAGTATGGAAGTCGTTCT NB14 AACGAGTCTCTTGGGACCCATAGA TCTATGGGTCCCAAGAGACTCGTT NB15 AGGTCTACCTCGCTAACACCACTG CAGTGGTGTTAGCGAGGTAGACCT NB16 CGTCAACTGACAGTGGTTCGTACT AGTACGAACCACTGTCAGTTGACG NB17 ACCCTCCAGGAAAGTACCTCTGAT ATCAGAGGTACTTTCCTGGAGGGT NB18 CCAAACCCAACAACCTAGATAGGC GCCTATCTAGGTTGTTGGGTTTGG NB19 GTTCCTCGTGCAGTGTCAAGAGAT ATCTCTTGACACTGCACGAGGAAC NB20 TTGCGTCCTGTTACGAGAACTCAT ATGAGTTCTCGTAACAGGACGCAA NB21 GAGCCTCTCATTGTCCGTTCTCTA TAGAGAACGGACAATGAGAGGCTC NB22 ACCACTGCCATGTATCAAAGTACG CGTACTTTGATACATGGCAGTGGT NB23 CTTACTACCCAGTGAACCTCCTCG CGAGGAGGTTCACTGGGTAGTAAG NB24 GCATAGTTCTGCATGATGGGTTAG CTAACCCATCATGCAGAACTATGC NB25 GTAAGTTGGGTATGCAACGCAATG CATTGCGTTGCATACCCAACTTAC NB26 CATACAGCGACTACGCATTCTCAT ATGAGAATGCGTAGTCGCTGTATG NB27 CGACGGTTAGATTCACCTCTTACA TGTAAGAGGTGAATCTAACCGTCG NB28 TGAAACCTAAGAAGGCACCGTATC GATACGGTGCCTTCTTAGGTTTCA NB29 CTAGACACCTTGGGTTGACAGACC GGTCTGTCAACCCAAGGTGTCTAG NB30 TCAGTGAGGATCTACTTCGACCCA TGGGTCGAAGTAGATCCTCACTGA NB31 TGCGTACAGCAATCAGTTACATTG CAATGTAACTGATTGCTGTACGCA NB32 CCAGTAGAAGTCCGACAACGTCAT ATGACGTTGTCGGACTTCTACTGG NB33 CAGACTTGGTACGGTTGGGTAACT AGTTACCCAACCGTACCAAGTCTG NB34 GGACGAAGAACTCAAGTCAAAGGC GCCTTTGACTTGAGTTCTTCGTCC NB35 CTACTTACGAAGCTGAGGGACTGC GCAGTCCCTCAGCTTCGTAAGTAG NB36 ATGTCCCAGTTAGAGGAGGAAACA TGTTTCCTCCTCTAACTGGGACAT NB37 GCTTGCGATTGATGCTTAGTATCA TGATACTAAGCATCAATCGCAAGC NB38 ACCACAGGAGGACGATACAGAGAA TTCTCTGTATCGTCCTCCTGTGGT NB39 CCACAGTGTCAACTAGAGCCTCTC GAGAGGCTCTAGTTGACACTGTGG NB40 TAGTTTGGATGACCAAGGATAGCC GGCTATCCTTGGTCATCCAAACTA NB41 GGAGTTCGTCCAGAGAAGTACACG CGTGTACTTCTCTGGACGAACTCC NB42 CTACGTGTAAGGCATACCTGCCAG CTGGCAGGTATGCCTTACACGTAG NB43 CTTTCGTTGTTGACTCGACGGTAG CTACCGTCGAGTCAACAACGAAAG NB44 AGTAGAAAGGGTTCCTTCCCACTC GAGTGGGAAGGAACCCTTTCTACT NB45 GATCCAACAGAGATGCCTTCAGTG CACTGAAGGCATCTCTGTTGGATC NB46 GCTGTGTTCCACTTCATTCTCCTG CAGGAGAATGAAGTGGAACACAGC NB47 GTGCAACTTTCCCACAGGTAGTTC GAACTACCTGTGGGAAAGTTGCAC NB48 CATCTGGAACGTGGTACACCTGTA TACAGGTGTACCACGTTCCAGATG NB49 ACTGGTGCAGCTTTGAACATCTAG CTAGATGTTCAAAGCTGCACCAGT NB50 ATGGACTTTGGTAACTTCCTGCGT ACGCAGGAAGTTACCAAAGTCCAT NB51 GTTGAATGAGCCTACTGGGTCCTC GAGGACCCAGTAGGCTCATTCAAC NB52 TGAGAGACAAGATTGTTCGTGGAC GTCCACGAACAATCTTGTCTCTCA NB53 AGATTCAGACCGTCTCATGCAAAG CTTTGCATGAGACGGTCTGAATCT NB54 CAAGAGCTTTGACTAAGGAGCATG CATGCTCCTTAGTCAAAGCTCTTG NB55 TGGAAGATGAGACCCTGATCTACG CGTAGATCAGGGTCTCATCTTCCA NB56 TCACTACTCAACAGGTGGCATGAA TTCATGCCACCTGTTGAGTAGTGA NB57 GCTAGGTCAATCTCCTTCGGAAGT ACTTCCGAAGGAGATTGACCTAGC NB58 CAGGTTACTCCTCCGTGAGTCTGA TCAGACTCACGGAGGAGTAACCTG NB59 TCAATCAAGAAGGGAAAGCAAGGT ACCTTGCTTTCCCTTCTTGATTGA NB60 CATGTTCAACCAAGGCTTCTATGG CCATAGAAGCCTTGGTTGAACATG NB61 AGAGGGTACTATGTGCCTCAGCAC GTGCTGAGGCACATAGTACCCTCT NB62 CACCCACACTTACTTCAGGACGTA TACGTCCTGAAGTAAGTGTGGGTG NB63 TTCTGAAGTTCCTGGGTCTTGAAC GTTCAAGACCCAGGAACTTCAGAA NB64 GACAGACACCGTTCATCGACTTTC GAAAGTCGATGAACGGTGTCTGTC NB65 TTCTCAGTCTTCCTCCAGACAAGG CCTTGTCTGGAGGAAGACTGAGAA NB66 CCGATCCTTGTGGCTTCTAACTTC GAAGTTAGAAGCCACAAGGATCGG NB67 GTTTGTCATACTCGTGTGCTCACC GGTGAGCACACGAGTATGACAAAC NB68 GAATCTAAGCAAACACGAAGGTGG CCACCTTCGTGTTTGCTTAGATTC NB69 TACAGTCCGAGCCTCATGTGATCT AGATCACATGAGGCTCGGACTGTA NB70 ACCGAGATCCTACGAATGGAGTGT ACACTCCATTCGTAGGATCTCGGT NB71 CCTGGGAGCATCAGGTAGTAACAG CTGTTACTACCTGATGCTCCCAGG NB72 TAGCTGACTGTCTTCCATACCGAC GTCGGTATGGAAGACAGTCAGCTA NB73 AAGAAACAGGATGACAGAACCCTC GAGGGTTCTGTCATCCTGTTTCTT NB74 TACAAGCATCCCAACACTTCCACT AGTGGAAGTGTTGGGATGCTTGTA NB75 GACCATTGTGATGAACCCTGTTGT ACAACAGGGTTCATCACAATGGTC NB76 ATGCTTGTTACATCAACCCTGGAC GTCCAGGGTTGATGTAACAAGCAT NB77 CGACCTGTTTCTCAGGGATACAAC GTTGTATCCCTGAGAAACAGGTCG NB78 AACAACCGAACCTTTGAATCAGAA TTCTGATTCAAAGGTTCGGTTGTT NB79 TCTCGGAGATAGTTCTCACTGCTG CAGCAGTGAGAACTATCTCCGAGA NB80 CGGATGAACATAGGATAGCGATTC GAATCGCTATCCTATGTTCATCCG NB81 CCTCATCTTGTGAAGTTGTTTCGG CCGAAACAACTTCACAAGATGAGG NB82 ACGGTATGTCGAGTTCCAGGACTA TAGTCCTGGAACTCGACATACCGT NB83 TGGCTTGATCTAGGTAAGGTCGAA TTCGACCTTACCTAGATCAAGCCA NB84 GTAGTGGACCTAGAACCTGTGCCA TGGCACAGGTTCTAGGTCCACTAC NB85 AACGGAGGAGTTAGTTGGATGATC GATCATCCAACTAACTCCTCCGTT NB86 AGGTGATCCCAACAAGCGTAAGTA TACTTACGCTTGTTGGGATCACCT NB87 TACATGCTCCTGTTGTTAGGGAGG CCTCCCTAACAACAGGAGCATGTA NB88 TCTTCTACTACCGATCCGAAGCAG CTGCTTCGGATCGGTAGTAGAAGA NB89 ACAGCATCAATGTTTGGCTAGTTG CAACTAGCCAAACATTGATGCTGT NB90 GATGTAGAGGGTACGGTTTGAGGC GCCTCAAACCGTACCCTCTACATC NB91 GGCTCCATAGGAACTCACGCTACT AGTAGCGTGAGTTCCTATGGAGCC NB92 TTGTGAGTGGAAAGATACAGGACC GGTCCTGTATCTTTCCACTCACAA NB93 AGTTTCCATCACTTCAGACTTGGG CCCAAGTCTGAAGTGATGGAAACT NB94 GATTGTCCTCAAACTGCCACCTAC GTAGGTGGCAGTTTGAGGACAATC NB95 CCTGTCTGGAAGAAGAATGGACTT AAGTCCATTCTTCTTCCAGACAGG NB96 CTGAACGGTCATAGAGTCCACCAT ATGGTGGACTCTATGACCGTTCAG -
Influenza primer sequences
Influenza A primer sequences described in the protocol originated from: Single-reaction genomic amplification accelerates sequencing and vaccine production for classical and Swine origin human influenza A viruses by Bin Zhou et al., 2009.
Component Sequence Tuni 12 ACGCGTGATCAGCAAAAGCAGG Tuni 12.4 ACGCGTGATCAGCGAAAGCAGG Tuni 13 ACGCGTGATCAGTAGAAACAAGG Influenza B primer sequences described in the protocol originated from: Universal influenza B virus genomic amplification facilitates sequencing, diagnostics, and reverse genetics by Bin Zhou et al., 2014.
Component Sequence B-PBs-UniF GGGGGGAGCAGAAGCGGAGC B-PBs-UniR CCGGGTTATTAGTAGAAACACGAGC B-PA-UniF GGGGGGAGCAGAAGCGGTGC B-PA-UniR CCGGGTTATTAGTAGAAACACGTGC B-HANA-UniF GGGGGGAGCAGAAGCAGAGC B-HANA-UniR CCGGGTTATTAGTAGTAACAAGAGC B-NP-UniF GGGGGGAGCAGAAGCACAGC B-NP-UniR CCGGGTTATTAGTAGAAACAACAGC B-M-Uni3F GGGGGGAGCAGAAGCACGCACTT B-Mg-Uni3F GGGGGGAGCAGAAGCAGGCACTT B-M-Uni3R CCGGGTTATTAGTAGAAACAACGCACTT B-NS-Uni3F GGGGGGAGCAGAAGCAGAGGATT B-NS-Uni3R CCGGGTTATTAGTAGTAACAAGAGGATT






