-
Basecalling options
We offer two options for basecalling Kit 12 data with sequencing accuracies of 99% and above (Q20+):
- Simplex basecalling, where the template DNA strand passes through the nanopore and is basecalled.
- Duplex basecalling, where the complement strand is read immediately after the template strand and the consensus basecall for both strands leads to a further increase in accuracy.
Each of these options is described in more detail in the "Basecalling Kit 12 data" subsections:
-
Alternatively, you can basecall in Guppy. For this, you will need to install Guppy version 5.1 or above.
To run Guppy basecalling on R10.4 data, specify one of the
dna_r10.4_e8.1config files, such asdna_r10.4_e8.1_fast.cfg,dna_r10.4_e8.1_hac.cfg, ordna_r10.4_e8.1_sup.cfg. For example:guppy_basecaller -c dna_r10.4_e8.1_fast.cfg [other Guppy arguments]For 9.4.1 data, specify one of the
dna_r9.4.1_450bpsconfig files, e.g.guppy_basecaller -c dna_r9.4.1_450bps_fast.cfg [other Guppy arguments] -
Basecall the data using Guppy version 5.1 or higher.
You can find instructions for setting up and running the Guppy software in the Guppy protocol.
-
Introduction to read splitting
With increased follow-on rates of the Kit 12 chemistry (the rate of the complement strand entering the pore directly after the template strand has passed through), we have observed a higher rate of concatemerisation compared to the Ligation Sequencing Kit (SQK-LSK110). We are classifying these reads as 'informatic chimeras' as they are not physically joined during the library preparation process.
With SQK-LSK110, we typically observe <2% concatemerisation and at this rate, it typically does not affect downstream applications. With, for example SQK-LSK112, we have observed a rate as high as 10%. Both MinKNOW (v21.11 and higher) and stand-alone Guppy (v5.1 and higher) now offer the option of splitting these reads.
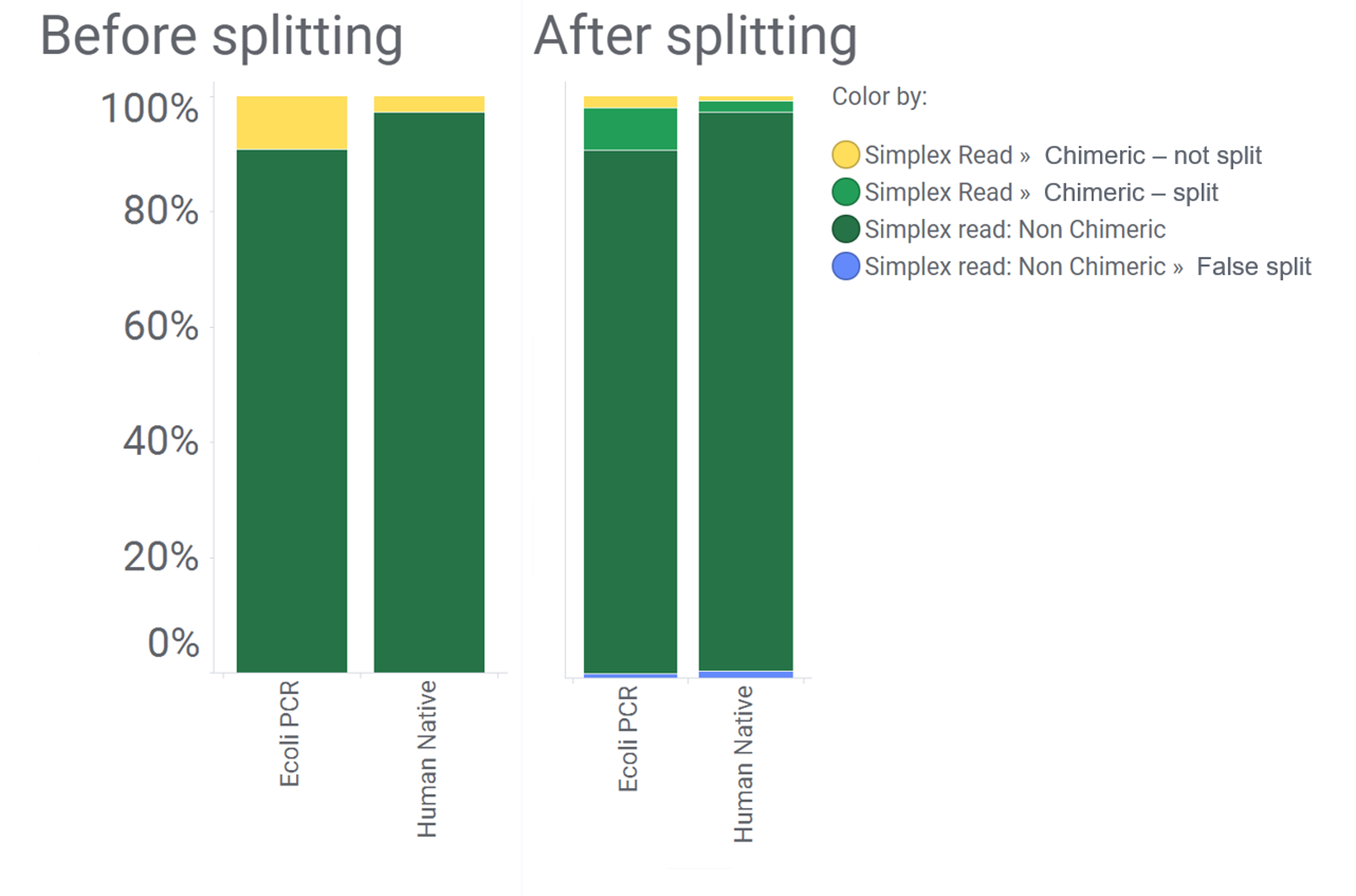
As you can see from the following example, the majority of the informatic chimeras (yellow) are removed after splitting for a human (native) and E. coli (PCR) sample.
It is important to note that the read splitting function is not designed to split reads that are incorrectly ligated together during sample preparation. While these make up a small percentage of reads, users should take care with ligation steps to follow the protocol carefully to reduce the chance of creating them.
-
Enable read splitting in Guppy
To enable read splitting in Guppy, use the
--do_read_splittingparameter when setting up your basecalling run. You can also limit the number of times a read will be passed into the read splitter (--max_read_split_depth) and set a minimum read splitting score (--min_score_read_splitting). For more information, refer to the "Setting up a run: configurations and parameters" section of the Guppy protocol.

